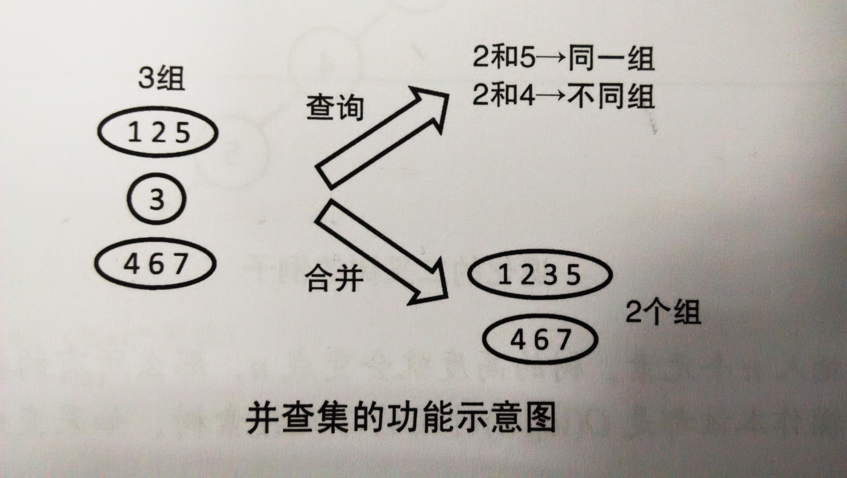
并查集 概述 并查集是一种用来管理元素分组情况的数据结构。冰茶既可以高效的进行如下操作。不过需要注意并查集虽然可以进行合并操作,但是却无法进行分割操作。 并查集可以查询元素a和元素b是否属于同一组。 并查集可以合并元素a和元素b所在的组。
主要操作 初始化 把每个点所在集合初始化为其自身。
1 2 3 4 5 void init () int i; for (i = 0 ; i < n; i++) par[i] = i; }
查找 查找元素所在的集合,即根节点。
1 2 3 4 5 int find (int x) if (par[x] != x) par[x] = find(par[x]); return par[x]; }
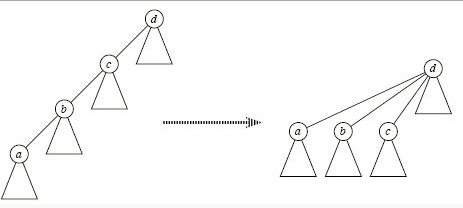
注意在这一步中通常采用路径优化,代码中 $par[x] = find(par[x])$ 即采用了路径优化,做了如图所示的转化,将所有的子节点都直接挂载在根节点上,使得接下来的查找更高效。
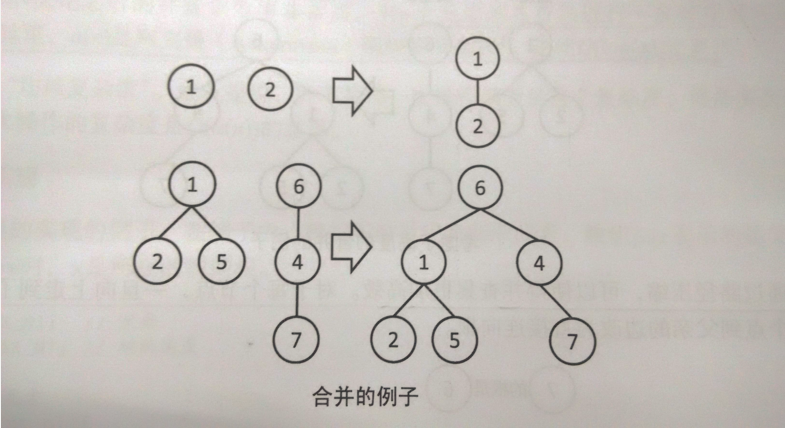
将两个元素所在的集合合并为一个集合。
1 2 3 4 5 6 void Union (int x, int y) int fx = find(x); int fy = find(y); if (fx != fy) par[fy] = fx; }
代码说明,先查找两个元素是否属于同一集合,即他们的根节点是否相同,若不相同就合并他们。
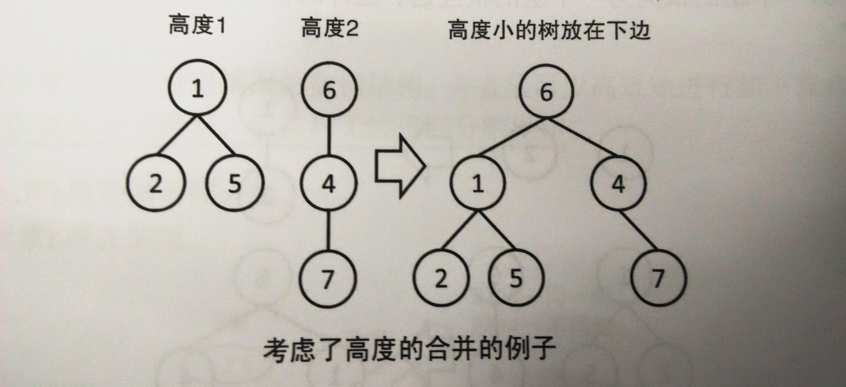
这里也可以进一步优化,对于每一个集合所形成的树,用一个rank[N] 数组来记录它的高度,合并时如果两棵树的高度不同,那么从rank 小的向rank 大的连边。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void Union (int x, int y) int fx = find(x); int fy = find(y); if (fx != fy){ if (rank[fx] >= rank[fy]){ par[fy] = fx; rank[fx]++; } else { par[fx] = fy; rank[fy]++; } } }
复杂度分析 在增加了路径优化和合并注意高度的优化后,并查集的效率非常高。可以证明,通过这种树形结构实现的带启发式路径压缩的并查集,Find和Union操作的平均代价是O(lgn),这和二分查找的复杂度一致,可以证明这已经是理论上最好的算法了,不可能有更好的算法了。如果不进行这种路经压缩的话,并查集就退化成了链表,在同一链表中的元素属于同一集合,这样的话Find的复杂度是O(n)。
POJ 例题分析 POJ 2524 题目大意: 有n 个数字,接下来会有m对数字,每一对数字属于同一类。
思路分析: 并查集的初级题目,可以用根节点的rank存储这一类的元素个数,子节点的rank全置为零,这样只要看有几个rank并不为零就可以确定这n个数字的种类数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <iostream> #define N 50005 using namespace std ;int par[N], rank[N]; int n, m;void init () int i; for (i = 1 ; i <= n; i++){ rank[i] = 1 ; par[i] = i; } } int find (int x) if (par[x] == x) return x; else return par[x] = find(par[x]); } void unite (int x, int y) x = find(x); y = find(y); if (x == y) return ; if (rank[x] > rank[y]){ rank[y] = 0 ; par[y] = x; rank[x] ++; } else if (rank[x] < rank[y]){ par[x] = y; rank[x] = 0 ; rank[y] ++; } else { par[y] = x; rank[y] = 0 ; rank[x] ++; } } int main () int i, j, x, y, sum, a = 0 ; while (cin >> n >>m){ if (n == 0 && m == 0 ) break ; a++; sum = 0 ; init(); for (i = 0 ; i < m; i++){ cin >> x >> y; unite(x, y); } for (i = 1 ; i <= n; i++){ if (rank[i] != 0 ) sum += 1 ; } cout <<"Case " << a <<": " << sum << endl ; } return 0 ; }
POJ 1703 题目大意: 将所有的数字分为两个部分并由输入的字符来确定要做的事情,其中A 来询问后面两个数的关系,D表示后面的两个数属于不同的类别。
输入的第一行是一个字母t, 代表测试样例数目,每个测试样例的第一行包括两个数,第一个数 n 代表数字的个数(编号1~n),第二个数 m 表示接下来有m 行,每一行包括一个字符’A’或’D’表示之后两个数的关系。
解题思路: 活用rank数组(代码中的rela数组)rank[i] = 0,表示节点 i 与根节点是同一类,rank[i] = 1表示节点 i 与根节点是不同类的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <iostream> #include <stdio.h> #define N 100005 using namespace std ;int par[N], rank[N], rela[N];int n, m;void init () int i; for (i = 1 ; i <= N; i++){ par[i] = i; rela[i] = 0 ; } } int find (int x) if (par[x] == x) return x; else { int temp = par[x]; par[x] = find(par[x]); rela[x] = (rela[temp] + rela[x]) % 2 ; return par[x]; } } void unit (int x, int y) int fx = find(x); int fy = find(y); if (fx == fy) return ; else { par[fy] = fx; rela[fy] = (rela[x] + 1 -rela[y]) % 2 ; } } void sol (int x, int y) if (find(x)== find(y) && rela[x] == rela[y]) printf ("In the same gang.\n" ); else if (find(y) == find(x) && rela[x] != rela[y]) printf ("In different gangs.\n" ); else printf ("Not sure yet.\n" ); return ; } int main () ios_base::sync_with_stdio(false ); int t, i, n, x, y; char ch; scanf ("%d" ,&t); while (t--){ scanf ("%d %d" , &n, &m); init(); for (i = 1 ; i <= m; i++){ getchar(); scanf ("%c %d %d" , &ch, &x, &y); if (ch == 'A' ) sol(x, y); else unit(x, y); } } return 0 ; }
网上还有一种很不可思议的解法,我自己也搞不懂为什么会这样,直接上代码了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <cstdio> #include <iostream> using namespace std ; int f[200001 ],n,m,x,y,cas; char c; int find (int x) if (x!=f[x]) f[x] = find(f[x]); return f[x]; } void Union (int x,int y) int px = find(x); int py = find(y); if (px != py) f[px] = py; } int main () scanf ("%d" ,&cas); while (cas--) { scanf ("%d%d" ,&n,&m); for (int i=1 ;i<=2 *n;i++) f[i] = i; for (int i=1 ;i<=m;i++) { scanf ("%c%c %d %d" ,&c,&c,&x,&y); if (c=='D' ) { Union(x,y+n); Union(y,x+n); } else { if (find(x)==find(y)) printf ("In the same gang.\n" ); else if (find(x)==find(y+n)||find(y)==find(x+n)) printf ("In different gangs.\n" ); else printf ("Not sure yet.\n" ); } } } return 0 ; }
POJ 1182 题目大意:(直接上题吧) 动物王国中有三类动物A,B,C,这三类动物的食物链构成了有趣的环形。A吃B, B吃C,C吃A。
第一行是两个整数N和K,以一个空格分隔。
Output 只有一个整数,表示假话的数目。
解题思路: 活用rank数组,rank[i] = 0 表示 i 与par[i] 是同类,rank[i] = 1 表示 i 吃par[i] , rank[i] = 2 表示par[i] 吃 i ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <cstdio> #define N 50005 using namespace std ;int par[N], rela[N]; int n, k, a, b; void init () int i; for (i = 1 ; i <= n; i++){ par[i] = i; rela[i] = 0 ; } } int find (int x) int y; if (par[x] == x) return x; y = par[x]; par[x] = find(y); rela[x] = (rela[x] + rela[y]) % 3 ; return par[x]; } void unit (int x, int y, int d) int fx = find(x); int fy = find(y); if (fx == fy) return ; else { par[fx] = fy; rela[fx] = (rela[y] - rela[x] + d + 3 ) % 3 ; } return ; } int main () int i, sum = 0 , d, fx, fy; scanf ("%d %d" ,&n,&k); init(); for (i = 1 ; i <= k; i++){ scanf ("%d %d %d" ,&d,&a,&b); if (a > n || b > n ||(d == 2 && a == b)) sum++; else { fx = find(a); fy = find(b); if (fx == fy && ((rela[a] - rela[b] + 3 ) % 3 != d - 1 )) sum++; else unit(a, b, d - 1 ); } } printf ("%d\n" ,sum); return 0 ; }