快速排序法 概述 快速排序(Quicksort)是对冒泡排序的一种改进。由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列.
基本操作 快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。步骤为:
从数列中挑出一个元素,称为 “基准”(pivot),
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。、
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
排序演示 假设用户输入了如下数组:
由于变量k已经储存了下标0的数据,所以我们可以放心的把下标0覆盖了。如此一来,下标3虽然有数据,但是相当于没有了,因为数据已经复制到别的地方了。于是我们再找一个数据来替换他。这次要变成找比k大的了,而且要从前往后找了。递加变量i,发现下标2是第一个比k大的,于是用下标2的数据7替换j指向的下标3的数据,数据状态变成下表:
重复上面的步骤,递减变量 j 。这时,我们发现 i 和 j “碰头”了:他们都指向了下标 2 。于是,循环结束,把 k 填回下标 2 里,即得到结果。 如果i和j没有碰头的话,就递加i找大的,还没有,就再递减j找小的,如此反复,不断循环。注意判断和寻找是同时进行的。
注意 :快速排序不会直接得到最终结果,只会把比k大和比k小的数分到k的两边。(你可以想象一下i和j是两个机器人,数据就是大小不一的石头,先取走i前面的石头留出回旋的空间,然后他们轮流分别挑选比k大和比k小的石头扔给对面,最后在他们中间把取走的那块石头放回去,于是比这块石头大的全扔给了j那一边,小的全扔给了i那一边。只是这次运气好,扔完一次刚好排整齐。)为了得到最后结果,需要再次对下标2两边的数组分别执行此步骤,然后再分解数组,直到数组不能再分解为止(只有一个数据),才能得到正确结果。
代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <time.h> #include <stdlib.h> using namespace std ;void swap (int *a, int *b) int t; t = *a; *a = *b; *b = t; } void quicksort (int *a, int l, int r) int t, i, j; if (l < r){ srand(time(NULL )); t = l + rand()%(r - l + 1 ); swap(&a[t], &a[l]); int base = a[l]; i = l, j = r; while (i < j) { while (i < j && a[j]>= base) j--; if (i < j) a[i++] = a[j]; while (i < j && a[i]< base) i++; if (i < j) a[j--] = a[i]; } a[i] = base; quicksort(a, l, i - 1 ); quicksort(a, i + 1 , r); } }
复杂度分析 快速排序的最坏情况基于每次划分对主元的选择。基本的快速排序选取第一个元素作为主元。这样在数组已经有序的情况下,每次划分将得到最坏的结果。一种比较常见的优化方法是随机化算法,即随机选取一个元素作为主元。这种情况下虽然最坏情况仍然是O(n^2),但最坏情况不再依赖于输入数据,而是由于随机函数取值不佳。实际上,随机化快速排序得到理论最坏情况的可能性仅为1/(2^n)。所以随机化快速排序可以对于绝大多数输入数据达到O(nlogn)的期望时间复杂度。一位前辈做出了一个精辟的总结:“随机化快速排序可以满足一个人一辈子的人品需求。” 随机化快速排序的唯一缺点在于,一旦输入数据中有很多的相同数据,随机化的效果将直接减弱。对于极限情况,即对于n个相同的数排序,随机化快速排序的时间复杂度将毫无疑问的降低到O(n^2)。解决方法是用一种方法进行扫描,使没有交换的情况下主元保留在原位置。
其他 C语言中可直接调用 qsort 快排函数,包含在 #include<algorithm> 头文件中, 它有四个参数,第一个为要排序的数组的 首地址,第二个参数为要排序的元素的个数,第三个参数为每个元素所占的空间大小,第四 个参数是需要自己写的比较函数,即告诉它应该按什么来排序.一种典型的写法如下: qsort(s,n,sizeof(s[0]),cmp) 下面具体介绍它的各种用法,主要是 cmp 函数的写法, cmp 函数有两个参数,均为 const void* 类型,有一个返回值,为 int 类型.
对一维整型数组排序: 1 2 3 int cmp (const void * a, const void *b) return *(int *)a - *(int *)b; }
如果整型数组为 a[] ,其中元素个数为n,则 qsort(a,n,sizeof(a[0]),cmp) 即完成了对 a[] 数组的 升序排序. 如果要按降序排列,可将 return (int )a - (int )b; 改为 return (int )b - (int )a;
对 char 类型数组排序: 1 2 3 4 5 6 int cmp (const void * a, const void * b) return *(char *)a - *(char *)b; } charword[100 ]; qsort(word,100 ,sizeof (word[0 ]),cmp);
对 double 类型数组排序: 1 2 3 4 5 double in[100 ]; int cmp (const void *a, const void *b) return *(double *)a > *(double *)b ? 1 : -1 ; } qsort(in,100 ,sizeof (in[0 ]),cmp);
值得注意的是,cmp 里不能像对 int 排序那样写 return *(double*)a - *(double*)b ,因为返回值 是整型,这样返回值是 double 会出错且不易察觉.
对字符串排序: 1 2 3 4 5 chars[100 ][100 ]; int cmp (const void * x, const void * y) return strcmp ((char *)x, (char *)y); } qsort(s, 100 , sizeof (s[0 ]), cmp);
对结构体一级排序: 1 2 3 4 5 6 7 8 9 10 struct node { int a, b; }s[100 ]; int cmp (const void *x, const void *y) node xx = *(node*)x; node yy= *(node*)y; return xx.a - yy.a; } qsort(s, 100 , sizeof (s[0 ]), cmp);
对结构体二级排序: 1 2 3 4 5 6 7 8 9 10 11 struct node { int a; int b; }s[100 ]; int cmp (const void * x, const void * y) node xx = *(node*)x; node yy = *(node*)y; if (xx.a != yy.a) return xx.a - yy.a; else return xx.b - yy.b; } qsort(s,100 ,sizeof (s[0 ]),cmp);
计算几何中求凸包的 cmp 1 2 3 4 5 6 7 8 9 int cmp (const void *a, const void *b) struct point *c = (point *)a ; struct point *d = (point *)b ; if (calc(*c,*d,p[1 ]) < 0 ) return 1 ; else if (!calc(*c, *d, p[1 ]) && dis(c -> x, c -> y, p[1 ].x, p[1 ].y) < dis(d -> x, d -> y, p[1 ].x, p[1 ].y)) return 1 ; else return -1 ; }
Sort cmp 函数的写法 默认排序顺序为从小到大 sort(arr, arr + n)
1 2 3 bool cmp (int a, int b) return a > b; }
排序的时候就写 sort(a,a+100,cmp);
1 2 3 4 5 struct node { int a; int b; double c; };
有一个 node 类型的数组 node arr[100] ,想对它进行排序:先按 a 值升序排列,如果 a 值相同,再按 b 值降序排列,如果 b 还相同,就按 c 降序排列。就可以写这样一个比较函数:
1 2 3 4 5 bool cmp (node x, node y) if (x.a != y.a) return x.a if (x.b != y.b) return x.b > y.b; return return x.c > y.c; }
排序时写 sort(arr,a+100,cmp);
归并排序 概述 归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个有序的子序列,再把有序的子序列合并为整体有序序列。归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。值得注意的是归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
基本操作 具体排序过程分成三个过程:
分解:将当前区间一分为二,即求分裂点 mid = (low + high)/2;
求解:递归地对两个子区间 array[low..mid] 和 array[mid + 1..high] 进行归并排序;递归的终结条件:子区间长度为 1(一个记录自然有序)。
合并:将已排序的两个子区间R[low..mid]和R[mid + 1..high]归并为一个有序的区间 array[low..high]。
申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
设定两个指针,最初位置分别为两个已经排序序列的起始位置
比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
重复步骤3直到某一指针到达序列尾
将另一序列剩下的所有元素直接复制到合并序列尾
代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> using namespace std ;int c[1010 ];void mergesort (int *a, int l, int r) int mid, i, j, k; if (r - l > 1 ){ mid = (l + r) / 2 ; mergesort(a, l, mid); mergesort(a, mid, r); i = l; j = mid; k = l; while (i < mid && j < r){ if (a[i] <= a[j]) c[k++] = a[i++]; else c[k++] = a[j++]; } for (; i < mid; i++) c[k++] = a[i]; for (; j < r; j++) c[k++] = a[j]; for (i = l; i < r; i++) a[i] = c[i]; } return ; } int main () int a[20 ] = {0 , 10 , 1 , 11 , 2 , 12 , 3 , 13 , 4 , 14 , 5 , 15 , 6 , 16 , 7 , 17 , 8 , 18 , 9 , 19 }; for (int i = 0 ; i < 20 ; i++) cout << a[i] <<" " ; cout << endl ; mergesort(a, 0 , 20 ); for (int i = 0 ; i < 20 ; i++) cout << a[i] <<" " ; cout << endl ; return 0 ; }
复杂度分析 时间复杂度为O(nlogn) 这是该算法中最好、最坏和平均的时间性能。空间复杂度为 O(n)比较操作的次数介于(nlogn) / 2和nlogn - n + 1。赋值操作的次数是(2nlogn)。归并算法的空间复杂度为:0 (n)归并排序比较占用内存,但却是一种效率高且稳定的算法。
其他作用(求逆序数) 修改合并排序在合并两个子序列时,出现右边元素小于左边元素的情况,亦即a[j] < a[i]时,出现逆序对。此时a[i+1…n1]里的元素均比a[j]大,而a[j]又在它们的后面。所以,此时的逆序对数:n1-i。后面的元素以此类推。
1 2 3 4 5 6 7 8 while (i < mid && j < r){ if (a[i] <= a[j]) c[k++] = a[i++]; else { c[k++] = a[j++]; ans += mid – i; } }
堆排序(详见数据结构, 堆) 简述 堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
基本操作 用大根堆排序的基本思想
先将初始文件R[1..n]建成一个大根堆,此堆为初始的无序区
再将关键字最大的记录R[1](即堆顶)和无序区的最后一个记录R[n]交换,由此得到新的无序区R[1..n-1]和有序区R[n],且满足R[1..n-1].keys≤R[n].key
由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆。然后再次将R[1..n-1]中关键字最大的记录R[1]和该区间的最后一个记录R[n-1]交换,由此得到新的无序区R[1..n-2]和有序区R[n-1..n],且仍满足关系R[1..n-2].keys≤R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
大根堆排序算法的基本操作:
初始化操作:将R[1..n]构造为初始堆;
每一趟排序的基本操作:将当前无序区的堆顶记录R[1]和该区间的最后一个记录交换,然后将新的无序区调整为堆(亦称重建堆)
注意:
只需做n-1趟排序,选出较大的n-1个关键字即可以使得文件递增有序。
用小根堆排序与利用大根堆类似,只不过其排序结果是递减有序的。堆排序和直接选择排序相反:在任何时刻堆排序中无序区总是在有序区之前,且有序区是在原向量的尾部由后往前逐步扩大至整个向量为止
代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <iostream> #include <cstdio> using namespace std ;int heap[20 ]; int n; void Minheapsortdown (int i, int m) int j, temp; temp = heap[i]; j = 2 * i + 1 ; while (j < m){ if (j + 1 < m && heap[j + 1 ] < heap[j]) j++; if (heap[j] >= temp) break ; heap[i] = heap[j]; i = j; j = 2 * i + 1 ; } heap[i] = temp; } void makeMinheap () int i; for (i = n / 2 - 1 ; i >= 0 ; i--) Minheapsortdown(I, n); } void Minheapsort () for (int i = n - 1 ; i >= 1 ; i--){ swap(&heap[0 ], &heap[i]); Minheapsortdown(0 , i); } } int main () int i; for (i = 0 ; i < 10 ; i++) heap[i] = -i; n = 10 ; for (i = 0 ; i < 10 ; i++) cout << heap[i] <<" " ; cout << endl ; makeMinheap(); for (i = 0 ; i < 10 ; i++) cout << heap[i] <<" " ; cout << endl ; Minheapsort(); for (i = 0 ; i < 10 ; i++) cout << heap[i] <<" " ; cout << endl ; return 0 ; }
复杂度分析 堆排序的时间,主要由建立初始堆和反复重建堆这两部分的时间开销构成,它们均是通过调用Heapify实现的。平均性能O(N*logN)。
其他性能 由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。堆排序是就地排序,辅助空间为O(1).它是不稳定的排序方法。
STL 中的堆排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <iostream> #include <algorithm> #include <cstdio> #include <vector> using namespace std ;bool cmp (int a, int b) return a > b; } void print (int elem) cout << elem << ' ' ; } int main () int n; vector <int > hea; while (cin >> n && n) hea.push_back(n); printf ("%s\n" , "After make_heap: " ); make_heap(hea.begin(), hea.end(), cmp); for_each(hea.begin(), hea.end(), print); printf ("\n" ); printf ("%s\n" , "After sort_heap: " ); sort_heap(hea.begin(), hea.end(), cmp); for_each(hea.begin(), hea.end(), print); printf ("\n" ); return 0 ; }
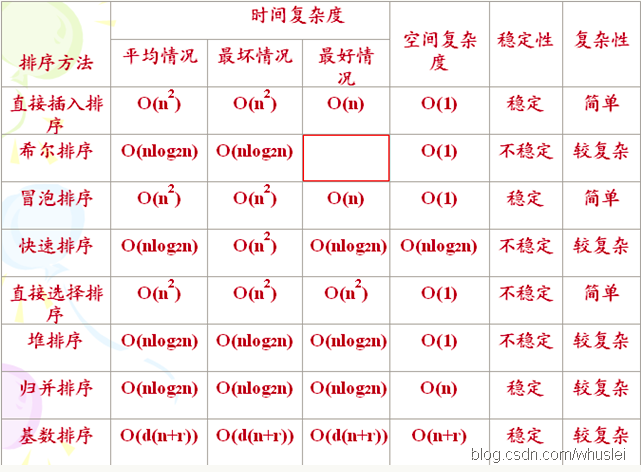
以上四种排序算法的总结 时空复杂度和稳定性
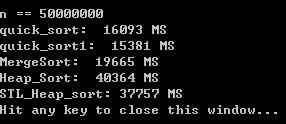
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 #include <cstdio> #include <algorithm> #include <ctime> using namespace std ; void quick_sort (int s[], int l, int r) if (l < r) { int i = l, j = r, x = s[l]; while (i < j) { while (i < j && s[j] >= x) j--; if (i < j) s[i++] = s[j]; while (i < j && s[i] < x) i++; if (i < j) s[j--] = s[i]; } s[i] = x; quick_sort(s, l, i - 1 ); quick_sort(s, i + 1 , r); } } void swap (int *a, int *b) int t; t = *a; *a = *b; *b = t; } void quick_sort1 (int *a, int l, int r) int t, i, j; if (l < r){ srand(time(NULL )); t = l + rand()%(r - l + 1 ); swap(&a[t], &a[l]); int base = a[l]; i = l, j = r; while (i < j) { while (i < j && a[j]>= base) j--; if (i < j) a[i++] = a[j]; while (i < j && a[i]< base) i++; if (i < j) a[j--] = a[i]; } a[i] = base; quick_sort(a, l, i - 1 ); quick_sort(a, i + 1 , r); } } void mergearray (int a[], int first, int mid, int last, int temp[]) int i = first, j = mid + 1 ; int m = mid, n = last; int k = 0 ; while (i <= m && j <= n) { if (a[i] < a[j]) temp[k++] = a[i++]; else temp[k++] = a[j++]; } while (i <= m) temp[k++] = a[i++]; while (j <= n) temp[k++] = a[j++]; for (i = 0 ; i < k; i++) a[first + i] = temp[i]; } void mergesort (int a[], int first, int last, int temp[]) if (first < last) { int mid = (first + last) / 2 ; mergesort(a, first, mid, temp); mergesort(a, mid + 1 , last, temp); mergearray(a, first, mid, last, temp); } } bool MergeSort (int a[], int n) int *p = new int [n]; if (p == NULL ) return false ; mergesort(a, 0 , n - 1 , p); return true ; } inline void Swap (int &a, int &b) int c = a; a = b; b = c; } void MinHeapFixdown (int a[], int i, int n) int j, temp; temp = a[i]; j = 2 * i + 1 ; while (j < n) { if (j + 1 < n && a[j + 1 ] < a[j]) j++; if (a[j] >= temp) break ; a[i] = a[j]; i = j; j = 2 * i + 1 ; } a[i] = temp; } void MakeMinHeap (int a[], int n) for (int i = n / 2 - 1 ; i >= 0 ; i--) MinHeapFixdown(a, i, n); } void MinheapsortTodescendarray (int a[], int n) for (int i = n - 1 ; i >= 1 ; i--) { Swap(a[i], a[0 ]); MinHeapFixdown(a, 0 , i); } } const int MAXN = 5000000 ; int a[MAXN]; int b[MAXN], c[MAXN], d[MAXN], e[MAXN]; int main () int i; srand(time(NULL )); for (i = 0 ; i < MAXN; ++i) a[i] = rand() * rand(); for (i = 0 ; i < MAXN; ++i) e[i] = d[i] = c[i] = b[i] = a[i]; clock_t ibegin, iend; printf ("n == %d\n" , MAXN); printf ("quick_sort: " ); ibegin = clock(); quick_sort(a, 0 , MAXN - 1 ); iend = clock(); printf ("%d MS\n" , iend - ibegin); printf ("quick_sort1: " ); ibegin = clock(); quick_sort(e, 0 , MAXN - 1 ); iend = clock(); printf ("%d MS\n" , iend - ibegin); printf ("MergeSort: " ); ibegin = clock(); MergeSort(b, MAXN); iend = clock(); printf ("%d MS\n" , iend - ibegin); printf ("Heap_Sort: " ); ibegin = clock(); MakeMinHeap(c, MAXN); MinheapsortTodescendarray(c, MAXN); iend = clock(); printf ("%d MS\n" , iend - ibegin); printf ("STL_Heap_sort: " ); ibegin = clock(); make_heap(d, d + MAXN); sort_heap(d, d + MAXN); iend = clock(); printf ("%d MS\n" , iend - ibegin); return 0 ; }
程序运行结果
拓扑排序 概述 一个较大的工程往往被划分成许多子工程,我们把这些子工程称作活动(activity)。在整个工程中,有些子工程(活动)必须在其它有关子工程完成之后才能开始,也就是说,一个子工程的开始是以它的所有前序子工程的结束为先决条件的,但有些子工程没有先决条件,可以安排在任何时间开始。为了形象地反映出整个工程中各个子工程(活动)之间的先后关系,可用一个有向图来表示,图中的顶点代表活动(子工程),图中的有向边代表活动的先后关系,即有向边的起点的活动是终点活动的前序活动,只有当起点活动完成之后,其终点活动才能进行。通常,我们把这种顶点表示活动、边表示活动间先后关系的有向图称做顶点活动网(Activity On Vertex network),简称AOV网。对一个AOV网G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。
基本操作 由AOV网构造出拓扑序列的实际意义是:如果按照拓扑序列中的顶点次序,在开始每一项活动时,能够保证它的所有前驱活动都已完成,从而使整个工程顺序进行,不会出现冲突的情况。
选择一个入度为0的顶点并输出之;
从网中删除此顶点及所有出边。
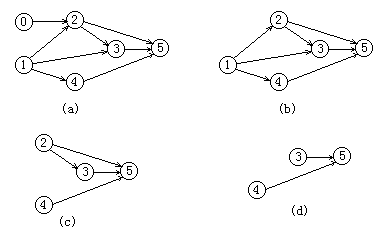
在(a)图中v0和v1的入度都为0,不妨选择v0并输出之,接着删去顶点v0及出边<0,2>,得到的结果如(b)图所示。
在(b)图中只有一个入度为0的顶点v1,输出v1,接着删去v1和它的三条出边<1,2>,<1,3>和<1,4>,得到的结果如(c)图所示。
在(c)图中v2和v4的入度都为0,不妨选择v2并输出之,接着删去v2及两条出边<2,3>和<2,5>,得到的结果如(d)图所示。
在(d)图上依次输出顶点v3,v4和v5,并在每个顶点输出后删除该顶点及出边,操作都很简单,不再赘述。为了利用C++语言在计算机上实现拓扑排序算法,AOV网采用邻接表表示较方便。如对于上图(a),对应的邻接表如下图2.
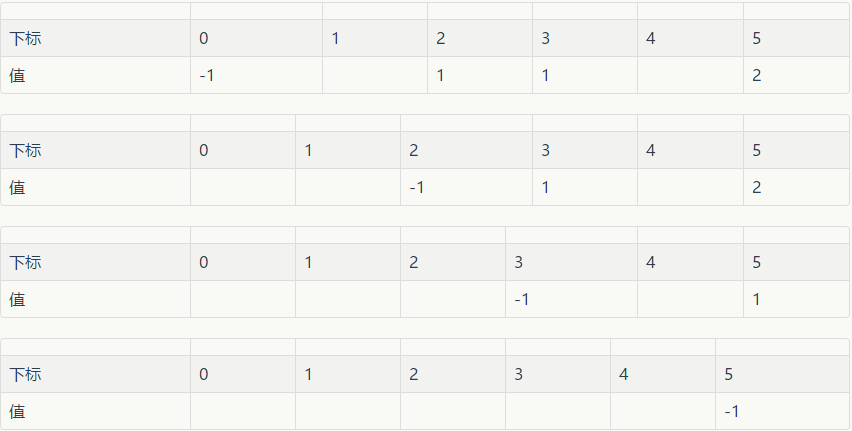
在拓扑排序算法中,需要设置一个包含n个元素的一维整型数组,假定用d表示,用它来保存AOV网中每个顶点的入度值。如对于上图(a),得到数组d的初始值为
开始置链栈为空,即给链栈指针top赋初值为-1: top=-1;
将入度为0的元素d[0]进栈,即: d[0]=top; top=0; 此时top指向d[0]元素,表示顶点v0的入度为0,而d[0]的值为-1,表明为栈底。
将入度为0的元素d[1]进栈,即: d[1]=top; top=1;此时top指向d[1]元素,表示顶点v1的入度为0,而d[1]的值为0,表明下一个入度为0的元素为d[0],即对应下一个入度为0的顶点为v0,d[0]的值为-1,所以此栈当前有两个元素d[1]和d[0]。
因d[2]至d[5]的值均不为0,即对应的v2到v5的入度均不为0,所以它们均不进栈,至此,初始栈建立完毕,得到的数组d为:
对于上表,当删除由top值所代表的顶点v1及所有出边后,数组d变为:
代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <vector> #include <cstdio> #include <iostream> #include <algorithm> #define M 110 using namespace std ;vector <int > vec[M]; int ingree[M]; int ans[M]; int n, m; bool TOSort () int i, j; int top = -1 ; int count = 0 ; fill(ingree, ingree + M, 0 ); for (i = 1 ; i <= n; i++){ int end = vec[i].size(); for (j = 0 ; j < end; j++) ingree[vec[i][j]]++; } for (i = 1 ; i <= n; i++) if (ingree[i] == 0 ){ ingree[i] = top; top = i; } while (top != -1 ){ int t = top; top = ingree[t]; ans[count++] = t; int end = vec[t].size(); for (i = 0 ; i < end; i++){ ingree[vec[t][i]]--; if (ingree[vec[t][i]] == 0 ){ ingree[vec[t][i]] = top; top = vec[t][i]; } } } if (count < n) return false ; return true ; } int main () int i, a, b; scanf ("%d%d" , &n, &m); for (i = 0 ; i < m; i++){ scanf ("%d%d" , &a, &b); vec[a].push_back(b); } if (TOSort()) for (i = 0 ; i < n; i++) printf ("%d%c" , ans[i], i == n - 1 ? '\n' : ' ' ); else printf ("有环\n" ); return 0 ; }
复杂度分析 拓扑排序实际上是对邻接表表示的图G进行遍历的过程,每次访问一个入度为0的顶点。若图G中没有回路,则需要扫描邻接表中的所有边结点,再加上在算法开始时,为建立入度数组d需要访问表头向量中的每个域和其单链表中的每个结点,所以此算法的时间复杂性为O(n+e)。
例题 题目描述: 输入的第一行有两个数字, n 和 m, n 指有n 个字母(从A开始的n 个), m 表示有m条信息, 接下来的m行信息的格式为: 字母1<字母2(例如A<B), m条信息后, 会有三种可能, 在第i个信息就能判断出n个字母的排序输出” Sorted sequence determined after i relations: ABCD…..”, 中间出现矛盾(A<B, B<A), 输出” Inconsistency found after i relations.”, 或者最终也没有一个唯一的排序输出” Sorted sequence cannot be determined.”
解题思路: 需要注意的是题目要求输出的几种情况的优先级, 首先优先级最高的是出现矛盾, 也就是如果出现了答案不唯一的情况之后出现了矛盾,那最终答案为矛盾; 如果拓扑序唯一确定之后出现了矛盾, 那最终答案为输出拓扑序.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 #include <queue> #include <cstdio> #include <cstring> #include <iostream> using namespace std ;const int MAXN = 30 ;const int MAXM = 1010 ;struct Edge { int v, nxt; }; bool vis[MAXN];Edge edge[MAXM]; int n, m, ecnt, num;int head[MAXN], deg[MAXN], res[MAXN];void init () num = ecnt = 0 ; memset (vis, 0 , sizeof (vis)); memset (res, 0 , sizeof (res)); memset (edge, 0 , sizeof (edge)); memset (head, -1 , sizeof (head)); } void addEdge (int u, int v) edge[ecnt].v = v; edge[ecnt].nxt = head[u]; head[u] = ecnt++; } int toSort () queue <int > que; memset (deg, 0 , sizeof (deg)); for (int u = 0 ; u < 26 ; u++) for (int i = head[u]; i + 1 ; i = edge[i].nxt) deg[edge[i].v]++; for (int i = 0 ; i < 26 ; i++) if (!deg[i] && vis[i]) que.push(i); int cnt = 0 ; bool flag = false ; while (!que.empty()){ if (que.size() > 1 ) flag = true ; int top = que.front(); que.pop(); res[cnt++] = top; for (int i = head[top]; i + 1 ; i = edge[i].nxt){ if (deg[edge[i].v] && vis[edge[i].v]){ deg[edge[i].v]--; if (deg[edge[i].v] == 0 && vis[edge[i].v]) que.push(edge[i].v); } } } if (cnt != num) return -1 ; else if (flag) return 0 ; else return cnt; } int main () while (scanf ("%d%d" , &n, &m) != EOF){ if (!(n + m)) break ; init(); char a, b; int ans = 0 , dx = 0 ; for (int i = 1 ; i <= m; i++){ scanf (" %c<%c" , &a, &b); if (!vis[a - 'A' ]) vis[a - 'A' ] = true , num++; if (!vis[b - 'A' ]) vis[b - 'A' ] = true , num++; addEdge(a - 'A' , b - 'A' ); if (ans == 0 ){ int tmp = toSort(); if (tmp == -1 ) ans = tmp, dx = i; else if (tmp == n && ans == 0 ) ans = tmp, dx = i; } } if (ans == -1 ) printf ("Inconsistency found after %d relations.\n" , dx); else if (ans){ printf ("Sorted sequence determined after %d relations: " , dx); for (int i = 0 ; i < n; i++) printf ("%c" , res[i] + 'A' ); printf (".\n" ); } else printf ("Sorted sequence cannot be determined.\n" ); } return 0 ; }
题目描述: 标号为 1~n 的 N 个球,满足给定的 M 个编号约束关系,输出最终满足关系的球的标号。
解题思路:
相互之间有一定的约束关系,会联系到拓扑排序,如果利用拓扑排序去解决本题还需要一定的贪心思想;
因为要保证标号小的球靠前的优先级越高,所以对于正向图拓扑排序,无法满足,比如:<1, 4> <4, 2> <3, 5>
对于反向拓扑排序,用同样的方法只需要保证标号大的球尽量靠后就行了,具体见代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <vector> #include <cstdio> #include <algorithm> using namespace std ;const int MAXN = 210 ;vector <int > G[MAXN];int arr[MAXN], indeg[MAXN];bool judge (int u, int v) for (int i = 0 ; i < G[u].size(); i++) if (G[u][i] == v) return false ; return true ; } int main () int cases; scanf ("%d" , &cases); while (cases--) { int n, m; scanf ("%d%d" , &n, &m); for (int i = 1 ; i <= n; i++) G[i].clear(), indeg[i] = 0 ; while (m--) { int u, v; scanf ("%d%d" , &v, &u); if (judge(u, v)) { G[u].push_back(v); indeg[v] += 1 ; } } int w; for (w = n; w >= 1 ; w--) { int i; for (i = n; i >= 1 ; i--) if (!indeg[i]) break ; if (i == 0 ) break ; arr[i] = w; indeg[i] = -1 ; for (int j = 0 ; j < G[i].size(); j++) { int v = G[i][j]; if (indeg[v] > 0 ) indeg[v] -= 1 ; } } if (w != 0 ) printf ("-1\n" ); else { for (int i = 1 ; i <= n; i++) printf ("%d%c" , arr[i], i == n ? '\n' : ' ' ); } } return 0 ; }



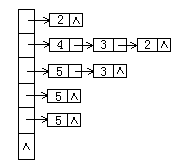
 在进行拓扑排序中,为了把所有入度为0的顶点都保存起来,而且又便于插入、删除以及节省存储,最好的方法是把它们链接成一个栈. 这里有两种方法,一种是再重新建一个栈用来存储入度为0 的点,另一种是直接用 d 数组来模拟栈操作,下面只介绍第二种。
在进行拓扑排序中,为了把所有入度为0的顶点都保存起来,而且又便于插入、删除以及节省存储,最好的方法是把它们链接成一个栈. 这里有两种方法,一种是再重新建一个栈用来存储入度为0 的点,另一种是直接用 d 数组来模拟栈操作,下面只介绍第二种。
 当依次删除top所表示的每个顶点及所有出边后,数组d的变化分别如下图所示:
当依次删除top所表示的每个顶点及所有出边后,数组d的变化分别如下图所示: