本文是博主学习 MIT6.824 课程的学习笔记,其中会总结论文知识点并加入自己的理解,内容可能与论文原文有出入,想要了解细节的读者可以阅读论文原文或者学习 MIT6.824课程。
MapReduce: Simplified Data Processing on Large Clusters
简介
MapReduce 是一种编程模型,也是一个处理和生成超大数据集算法模型的相关实现。使用 MapReduce 架构的程序能够在大量的普通配置的计算机上实现并行化处理。
MapReduce 模型
MapReduce 编程模型的处理过程为:输入一个 key/value pair 集合,经过处理后,输出一个 key/value pair 集合作为结果。MapReduce 允许用户使用两个函数 Map 和 Reduce 来表达上述计算。
Map函数接受一个输入的key/value pair值,然后产生一个中间key/value pair值的集合。MapReduce把所有key为I的中间值value集合在一起后传递给reduce函数。Reduce函数接受一个中间key的值I和其value值的集合,由于value值可能由于太大无法放入内存中,故通常我们把value的迭代器传递给Reduce函数。
上述过程也可以抽象为下面的表达式
$$ map(k1, v1) -> list(k2, v2) $$
$$ reduce(k2, list(v2)) -> list(v2) $$
一个例子
下面的例子可以简要说明 MapReduce 模型的计算过程,当我们要计算一个很大的文档集合中每个单词出现的次数时,可以用下面的方式:
1 | map(String key, String value): |
Map 函数输出文档中的每个词、以及这个词的出现次数(在这个简单的例子里就是 1)。Reduce 函数把 Map 函数产生的每一个特定的词出现的次数累加起来。
实现
执行过程
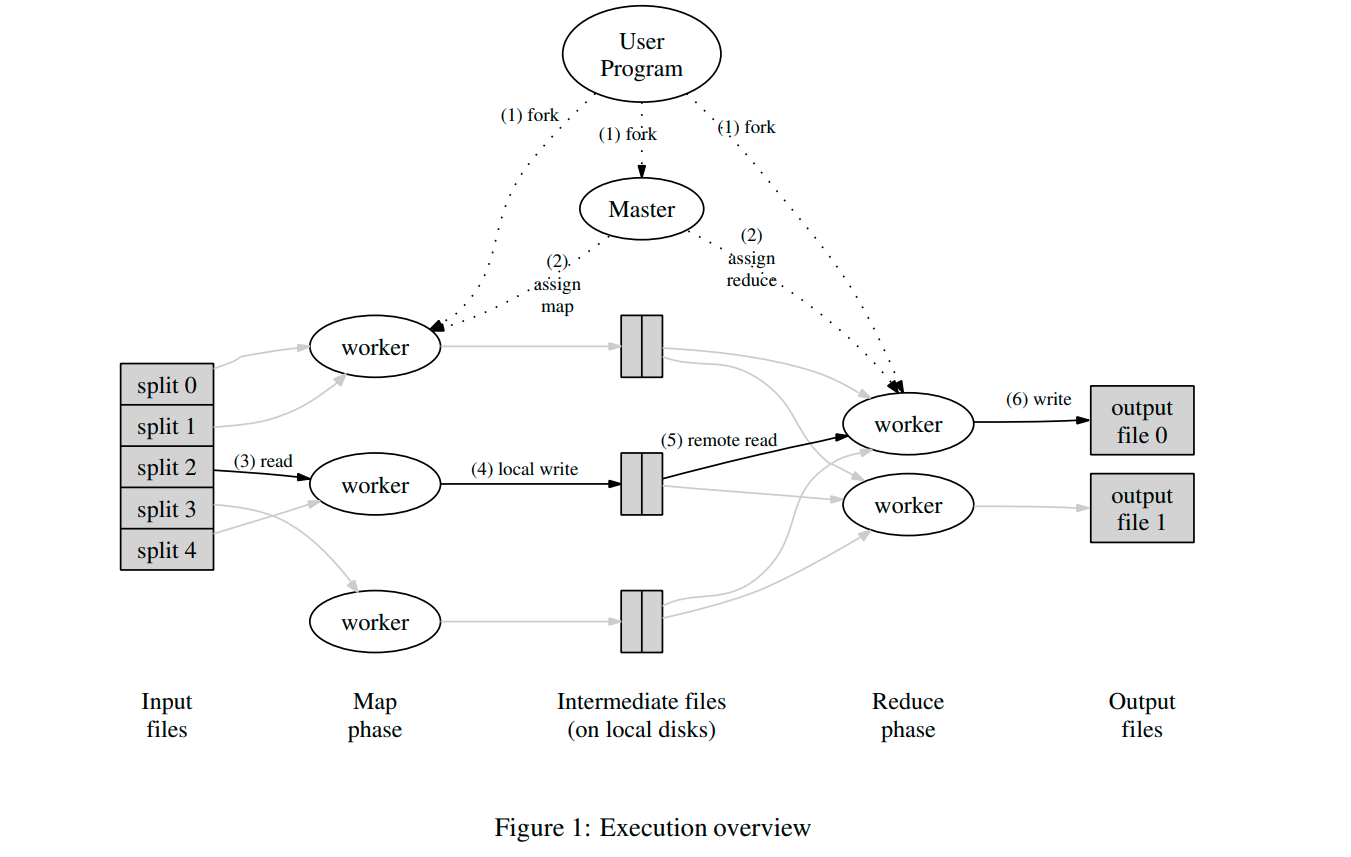
图 1 展示了 MapReduce 的计算流程。当用户调用 MapReduce 函数时,将发生下面的一 系列动作(下面的序号和图 1 中的序号一一对应):
用户程序首先调用
MapReduce库将输入文件分成M 个数据片度,每个数据片段的大小一般从16MB 到 64MB(可以通过可选的参数来控制每个数据片段的大小)。然后用户程序在机群中创建大量的程序副本。这些程序副本中的有一个特殊的程序–
master。副本中其它的程序都是worker程序,由master分配 任务。有M 个 Map 任务和R 个 Reduce 任务将被分配,master将一个Map任务或Reduce任务分配给一个空闲的worker。被分配了
Map任务的worker程序读取相关的输入数据片段,从输入的数据片段中解析出key/value pair,然后把key/value pair传递给用户自定义的Map函数,由Map函数生成并输出的中间key/value pair,并缓存在内存中。缓存中的
key/value pair通过分区函数分成R个区域,之后周期性的写入到本地磁盘上。缓存的key/value pair在本地磁盘上的存储位置将被回传给master,由master负责把这些存储位置再传送给Reduce worker。当
Reduce worker程序接收到master程序发来的数据存储位置信息后,使用RPC从Map worker所在主机的磁盘上读取这些缓存数据。当Reduce worker读取了所有的中间数据后,通过对key进行排序,使得具有相同key值的数据聚合在一起。由于许多不同的key值会映射到相同的Reduce任务上, 因此必须进行排序。如果中间数据太大无法在内存中完成排序,那么就要在外部进行排序。Reduce worker程序遍历排序后的中间数据,对于每一个唯一的中间key值,Reduce worker程序将这 个key值和它相关的中间value值的集合传递给用户自定义的Reduce函数。Reduce函数的输出被追加到所属分区的输出文件。当所有的
Map和Reduce任务都完成之后,master唤醒用户程序。在这个时候,在用户程序里的对MapReduce调用才返回。
在成功完成任务之后MapReduce 的输出存放在 R 个输出文件中(对应每个 Reduce 任务产生一个输出文件,文件名由用户指定)。一般情况下,用户不需要将这 R 个输出文件合并成一个文件–他们经常把这些文 件作为另外一个 MapReduce 的输入,或者在另外一个可以处理多个分割文件的分布式应用中使用。
在上述执行过程中,master 会记录每一个 Map 和 Reduce 任务的当前完成状态,以及所分配的 worker。除此之外,Mmster 还负责将 Map 产生的中间结果文件的位置和大小转发给 Reduce。
容错机制
worker 失效
master 会周期性的 ping worker,如果 worker 没有及时返回信息,则 master会将其标记为失效。对于在该 worker上执行的任务,分为以下几种情况:
已经完成的
Map任务:由于Map任务的输出已经无法被访问,故该任务会被重置为空闲状态,后续将被安排给其他的worker重新执行,并且重新执行的动作会通知给所有执行Reduce的worker。任何还没有从失效worker上读取数据的Reduce任务后续将从新的worker上读取。已经完成的
Reduce任务:由于Reduce的输出结果会存储在全局文件系统上,故无需再次执行。该设定是基于 Google 的使用场景,Google 会将 Reduce 任务的输出结果放在 GFS 上,故无需担心数据丢失问题,如果将结果放在本地文件,则仍需要重新执行 Reduce 任务。
正在运行的
Map和Reduce任务:将会被重置为空闲状态,等待重新调度。
master 失效
master 会周期性的将其维护的数据结构(点击跳转) 写入磁盘(即检查点 checkpoint),当前 master 失效时,将会重新启动一个 master 并从检查点记录的状态继续执行。
在 Google 内部的实现中,如果 master 失效,就中止 MapReduce 运算,由人工干预恢复 master 状态。
对于上述机制的讨论
当用户定义的 Map-Reduce 函数都是确定性函数的时候,相同的输入具有相同的输出,所以重复执行具有相同的结果,上述容错机制最终都可以得到正确的结果。
但当用户定义的 Map-Reduce 函数非确定性函数时,两个 Reduce 可能会输入来自两个不同 Map(但是 Map 函数的输入是相同的) 的结果,此时 Reduce 函数的输出可能会不同。
优化技巧
存储与计算尽量在同一个节点
为了减少数据拉取带来的网络开销,在 Google 的使用场景下,会结合 GFS 的存储,尽可能的将 Map 任务调度到文件存储所在的,或者相邻的服务器上。
增加任务数以平衡负载
前面提到,在计算过程将 Map 拆成 M 个,Reduce 拆成 R 个来执行,理想情况下 M 和 R 应当远远大于 worker 的数量,这样可以让每个 worker 都可以执行大量不同的任务来实现动态的负载均衡,也可以在某个 worker 生效,任务转移到其他 worker 时不会造成热点。
但实际上需要考虑以下因素来限制 M 和 R 的值:
master节点需要执行 $O(M+R)$ 次调度,并且需要在内存中保存 $O(M*R)$ 个状态R值需要用户指定,因为它是最终结果的文件数目M值的大小决定了每个Map输入数据的数据量,通常我们向让每个输入数据在16MB~64MB之间
基于以上的原因,在 Google 的场景下,他们的 M R 与 worker 数量的比例一般为:$M=200000, R=5000, worker=2000$
处理落后任务
Map-Reduce 这样的分布式计算框架,最终受到木桶效应 的影响会很大,如果有个 worker由于 CPU 内存 磁盘 等因素的影响,导致执行速度缓慢,就会影响整个计算任务的进度。
为了解决上述问题,在 Map-Reduce 操作接近完成的时候,master会调度备用任务(backup)进程来执行剩下的,处于处理中(in-progress)的任务,当备用任务处理完成或者是原始任务处理完成,都会将这个任务标记为完成。
自定义分区函数
Map 任务执行完成后,Map-Reduce 框架会对Map 产生的 key 使用分区函数进行分区,以保证相同的 key 能够被分配到相同的 Reduce 任务,通常来说分区函数使用 hash 方法,比如 $hash(key) mod R$。但是对于某些场景,可能会有其他的分区需求,比如我们对 URL 进行统计时,如果我们想把相同域名的 URL 分到同一个 Reduce 任务,这时需要自定义分区函数。
Combiner 函数
在 Map 任务结束后,可能存在大量的重复 key 的 key/value pair,比如上述统计单词个数的任务,Map 结束后可能会出现大量 the <-> 1 这种 key/value pair。所有这些 key/value pair 都得通过网络发送给 Reduce 并由 Reduce 任务作累加。
为了减小网络传输和 Reduce 任务的工作量, Map-Reduce 框架支持用户指定一个 Combiner 函数在 Map 任务执行结束后,对 Map 任务的结果先做一次预处理,以将相同的 key 值合并在一起。

