摘要
本文主要讨论在 OLAP 领域,面向列的存储和计算为什么会比面向行的存储和计算更快的问题。
在 OLAP 场景下,基准测试都会说面向列的存储和计算比面向行的存储和计算块一个数量级。而大家普遍理解面向列快的原因是
column-stores are more I/O efficient for read-only queries since they only have to read from disk (or from memory) those attributes accessed by a query.
对于只读查询,列存储的I/O效率更高,因为它们只需要从磁盘(或内存)中读取查询所需要的那些字段。
这种想法让大家认为即使是行存也可以通过一些优化手段,达到列存的性能,包括:
- 垂直分表(vertically partitioning)
- 全列索引(indexing every column)
这些优化手段可以在查询时,只查询部分列对应的数据,从而加快分析速度。
通过一系列实验不难发现,这些手段并不能让面向行存打到列存的性能,原因是列存除了存储优势外,在计算上还有以下几种优化手段:
- 压缩(Compression)
- 延迟物化(Late Materialization)
- 快迭代(Block Iteration)
- Invisible Join
前三种手段是目前面向列的系统中已有的优化手段,最后一种是本文新提出的一种策略,后面的章节会详细介绍。
简介
近些年很多列存数据库系统的论文都通过一系列数据表明,在特定领域,特别是读密集型(read-intensive)分析处理的工作负载上,面向列的系统要比面向行的系统性能上要好一个数量级。但是这些面向列的系统性能测试方式显然过于“传统”,仍然以面向行的系统数据结构的设计思路来设计性能测试的方案,虽然能看出面向列系统的潜力,但没有回答大家对此最关键的疑惑:
Are these performance gains due to something fundamental about the way column-oriented DBMSs are internally architected, or would such gains also be possible in a conventional system that used a more column-oriented physical design?
面向列的系统好于面向行的系统,是因为面向列的系统内在基础架构(个人觉得是列式的存储格式)导致的吗?传统的系统能否通过一些面向列的物理设计(通过一些手段来达到列式存储的效果)来达到面向列的系统的性能?
本文将通过 Star Schema Benchmark (SSBM) 典型的数仓测试拓扑结构,在面向行的系统中,模拟列存的设计范式,来解答上述疑惑。模拟列式范式的设计有:
- 表结构垂直拆分(Vertically artitioning the tables),将表结构拆分为两元组的形式(key-value),来实现对于一个查询,只需要访问特定列的目标
- 仅从索引中提取数据的计划(Index-only plans),为每个表都创建一组索引,以确保可以覆盖所有查询中所需要的列,这样可以保证查询过程中直接从索引中提取字段的值
- 物化视图(Materialized views),针对所有查询做物化视图,以获取最佳的查询性能
经过上述模拟实验得出结论,即使在面向行的系统中应用了面向列的思路来设计存储范式,在分析场景下,性能仍然无法与面向列的系统抗衡。
在得到上述结论后,我们再来关注下一个问题
Which of the many column-database specific optimizations proposed in the literature are most responsible for the significant performance advantage of column-stores over row-stores on warehouse workloads?
在数仓场景下,究竟是哪些优化手段,让面向列的系统性能由于面向行的系统性能
这里直接给出了结论,面向列的系统中优化主要有:
- 延迟物化(Late Materialization)
- 基于块的迭代(Block Iteration)
- 压缩(Compression)
- 本文提出一个新的优化点 Invisible Joins
到这里,本文又提出了一个问题
However, because each of these techniques was described in a separate research paper, no work has analyzed exactly which of these gains are most significant.
定量来看,这几种优化手段分别可以提升多少性能呢?
在接下来的工作中,作者逐个移除 C-Store 数据库中的上述优化手段来进行测试,最终发现:
- 压缩带来的性能提升要看具体的数据,最多时可以提升一个数量级
- 延迟物化可以提高 3 倍
- 基于块的迭代和 Invisible Joins 可以提升约 1.5 倍
接下来的章节将分别讲述上述几个实验的细节。
面向行的执行
这一章将分别讨论垂直分表、全索引和物化视图设计对于面向行的系统的性能影响。
垂直分表(Vertical Partitioning)
垂直分表也就意味着同时也得有某种机制,可以将所有的字段再组合成之前的数据。第一反应可能需要在表中增加一个主键字段(primary key),但是主键字段可能会比较大,并且很多时候主键是复合主键,所以通常需要向每个表添加一个整数“position”列。但是查询中如果需要多个列,就得基于 position 列做额外的 join 操作。如果为了加速 join 再引入索引,则又会增加存储和 I/O 的开销,很难有优势。
全索引执行计划(Index-only plans)
垂直分表会引入两个新的问题:
- 它需要在每一列上增加一个
position字段用来还原之前的记录,这会浪费大量的磁盘空间和磁盘带宽 - 大多数行式存储在每个元组上会存储一个一个大的头部数据(a relatively large header on every tuple),这又进一步浪费了磁盘空间)
为了避免上述问题,我们考虑使用全索引计划。
为了不回原始表查数据,势必要将 query 中任意条件的字段,都通过对应字段的索引来过滤出各种的主键列表,然后做合并计算。如果某些字段对应的条件,无法被其索引快速过滤数据的话,就会导致索引的全扫描,且这样的扫描可能会有多次。最终造成多个索引扫描然后合并主键列的速度,还不如一趟扫描原始表数据并过滤。另外,元信息和头信息的大量冗余,也是造成巨大的性能损失。因此整体的存储、I/O开销都很大。
物化视图(materialization view)
完全根据预定义的SQL来生成确定的物化视图,且其中不会关联多余的列。显然这种方式查询性能很好(插入性能差),I/O效率高,但这种方法又只能应付极其有限的场景。
面向列的执行
这一章将分别讨论压缩、延迟物化、基于块的迭代以及 Invisible Join 带来的性能影响。
压缩(Compression)
所谓压缩,即将相似度很高、信息熵很低的数据放在一起,用更小的空间表达相同的信息量。所以压缩优化在列存系统上要比行存更加有效,因为对于列存来说同一列的数据被放在一起,同一列的数据往往类型相同,相同的特征更多,更容易被压缩。但是仅仅去追求高压缩比是没有意义的,可能还会导致计算效率下降。因为大多数算子,需要对数据解压缩后才能进行操作,越高的压缩比往往解压时性能越差。
压缩优化带来的优势有:
压缩后的数据量更小,可以减少硬盘存储空间,同时硬盘的数据量变少在读取时就可以减少 I/O 压力
有些时候解压缩的过程可以省略掉,从而直接对压缩后的数据进行操作。比如使用
Run-Length编码方式进行压缩的数据,就可以直接进行某些运算Run-Length 的压缩过程大概是,对于原始序列为 1, 1, 2, 2, 3, 3, 3 的数据,压缩后表达为 1 * 2, 2 * 2, 3 * 3。当我们要对这一列进行 sum 或者 count 运算时,原始数据可以直接转换为 sum(1 * 2 + 2 * 2 + 3 * 3) 和 count(2 + 2 + 3),不仅不需要解压缩,而且还提高了计算效率。
另外,压缩优化最好可以配合 sort 使用,如果数据是经过排序的,则更容易找到相邻数据的同质化特征,获得更好的压缩效果。
延迟物化(Late Materialization)
物化(materialization)的意思是说,为了把底层面向列的存储格式跟客户要求的格式(行式)对的上,需要在查询的某个阶段转换一下。
为什么需要物化这个过程呢?
往往一个查询只会涉及到部分列,在行存模式下,计算时需要将整行拿出来解析并提取需要的字段,并将其他字段丢掉。而在列存中,由于每列都是独立存储的,所以只需要读取查询所需要的列就可以了,这样的数据结构在内存中依然是以列为单位组织的,所以需要在计算的某个时刻将其变为一行为单位组织。
延迟物化的几点优势:
select和aggregation操作下其实不需要整行数据,此时过早物化会浪费- 如果数据是被压缩过的,物化的过程就必须对数据进行解压,这会影响压缩带来的好处
- 列式的内存组织形式对 CPU Cache 非常友好,从而提高计算效率,相反行式的组织形式因为非必要的列占用了 Cache Line 的空间,Cache 效率低。
- 针对定长的列做块迭代处理,可以当成一个数组来操作,可以利用CPU的很多优势(SIMD加速、cache line适配、CPU pipeline等);相反,行存中列类型往往不一样,长度也不一样,还有大量不定长字段,难以加速
块迭代计算(Block Iteration)
行存模型中,每一个算子在处理数据的时候,都要先迭代一条数据,然后通过定义的接口从数据中获取到某个字段的值,然后再对值进行操作。这个流程使得每处理一条数据就得额外调用一两次用来获取数据的函数(一般称为火山模型)。
而在列式存储中,每一次块迭代都可以获取到多条数据,并且当需要对某一列操作时,可以将一整块列的值传递给处理函数。同时不需要额外调用函数获取值,并且如果列是等宽的(fixed-width),可以直接作为数组来迭代。
使用上述方法时,可以充分利用 CPU 的很多优势(SIMD加速、cache line适配、CPU pipeline等)。
隐式连接(Invisible Join)
假如现在有这样的一些表结构
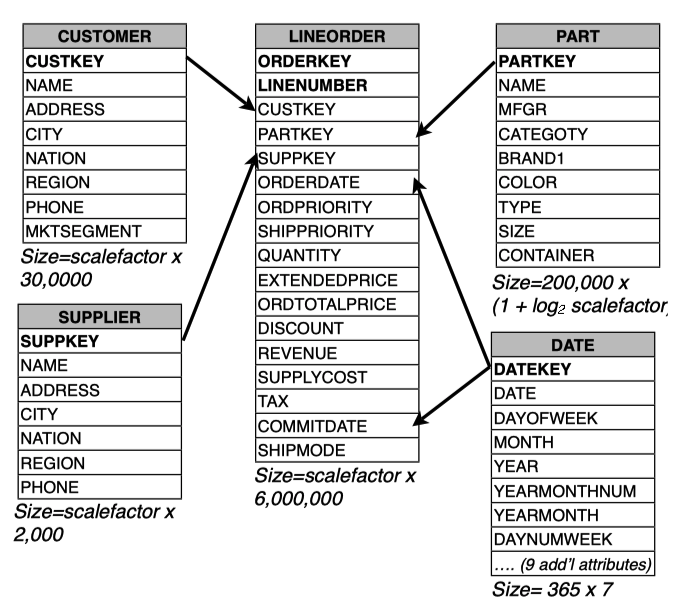
针对这个模型,我们给出一个 join 的场景,例如以下的 SQL
1 | SELECT c.nation, s.nation, d.year, sum(lo.revenue) as revenue |
一般来说,有以下两种方式来实现 join
按照 Selectivity 来 join
这种方式很简单,就是按照谓词的选择性来依次执行 join。
例如,c.region = 'ASIA' 的选择性很强,则首先使用这个条件过滤 customer 表,然后使用 customer 表去 join LineOrder 表,所以 customer 表中的 nation 字段就被增加到了 customer-order 表中。依次类推,去完成 supplier 和 date 表的 join。
这种方式的缺点为:一开始就开始做 join ,后续无法享受上面提到的延迟物化的好处。
传统延迟物化的 join
这个方式可以规避一开始做 join 的行为,具体方法为:
- 用
c.region = 'ASIA'过滤custom表,并拿到满足条件的custom key的集合,同时记录custom表中满足条件的记录的位置 - 用
1中获得的custom key来过滤orderline表,并拿到满足条件的记录的位置 - 遍历
2中获得的位置列表,提取suppplier key、order date和revenue并且借助custom key和1中获取到的位置信息,提取custom表中的c.nation字段 supplier和date表的join类似处理
这种方式的缺点为:在 3 中提取 c.nation 的操作为随机访问,会产生较大的开销。
Invisible join
Invisible Join 是本文新提出的一种方法,用于上文中提到的星型模型的 join 场景。它优化了传统延迟物化join 的缺点,尽可能减少随机读取的数据,从而提高性能。具体的执行步骤为:
在每个维度表上应用对应的过滤条件,得到每个维度表(
dimension table)满足条件的记录的key,同时这个key也应该是事实表(the fact table)的外键(foreign key)。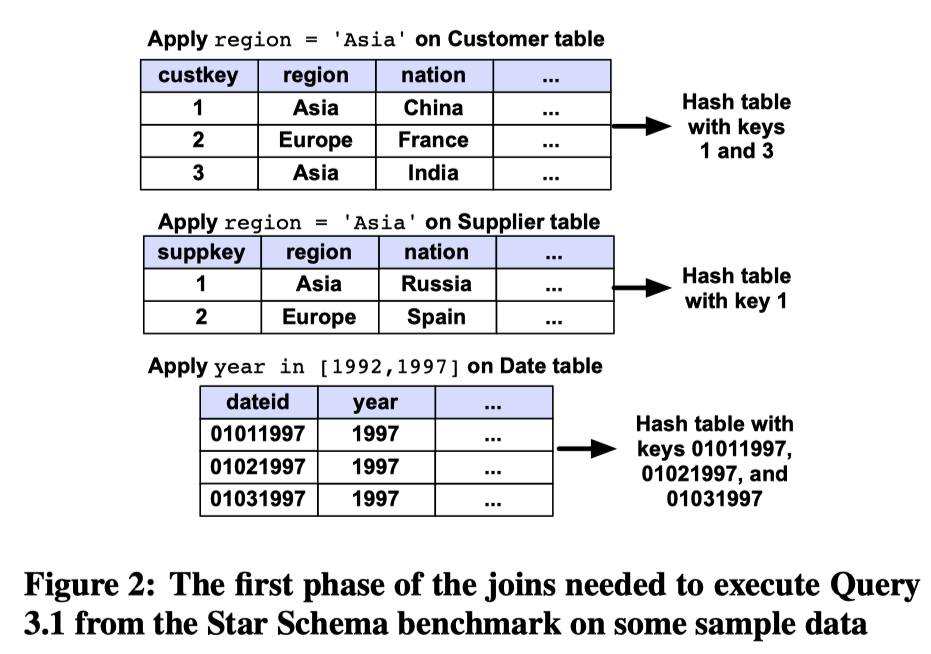
遍历事实表的各个外键列,使用
1中得到的key来判断是否满足条件,生成一个满足条件的记录的位置信息的bitmap,并将这些bitmap做AND操作,生成最终过滤结果的bitmap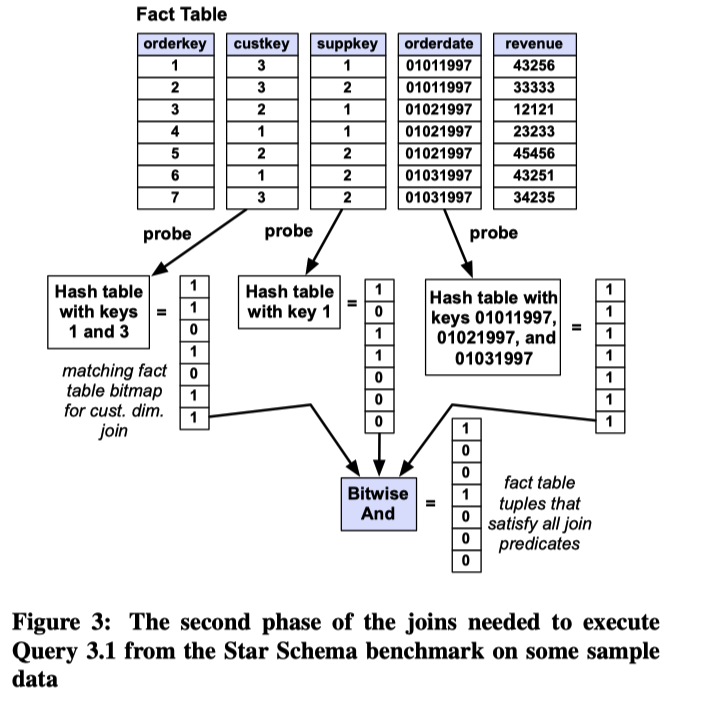
利用
2中得到的bitmap依次提取各个维度表的外键,使用维度表的键来提取维度表中查询所需要的其他列。如果维度表的键是排过序的、从1开始连续的值,意味着维度表里面的列可以通过类似访问数组一样的方式提取出来(这一点会比传统的延迟物化方法快很多)。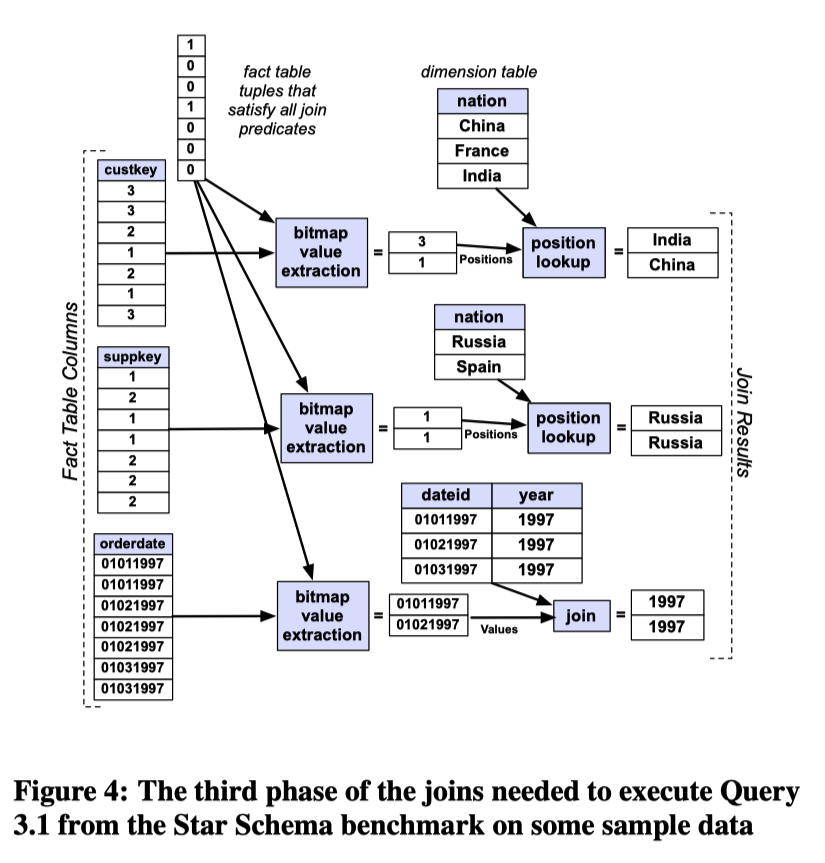
总结
总结本文的几个成果
- 展示了试图在行存储中模拟列存储不会产生良好的性能结果,并且各种通常被视为对仓库性能“有益”的技术(仅索引计划、位图索引等)对改善这种情况几乎没有帮助。
- 提出了一种用于提高列存的 join 性能的新技术,称为 invisible join。并通过实验证明,在多数情况下,使用此技术执行 join 的性能与从一个已实现连接的反范式化的表中选择和提取数据一样好,甚至更好。因此可以得出结论,面向行的系统在数据仓库场景中使用的反范式的优化手段,在列存储中完全没有必要(可以极大节省空间开销)。
- 分析了数仓场景下列存数据库性能的来源,探讨了延迟物化、压缩、块迭代和 invisible joins 对整体系统性能的贡献,并证明了简单的面向列操作(没有压缩和延迟物化)并没有显著优于做了优化的行存储设计。

