本文全部内容都来自于 DECODEZ “Skylake 微架构剖析” 系列,地址 https://decodezp.github.io/2019/01/07/quickwords9-skylake-pipeline-1/
搬运仅仅为了留作笔记,详细内容请直接访问 DECODEZ 的博客网站 https://decodezp.github.io/
前言
了解 CPU 的微架构是基于其开发“硬核”软件的必需步骤。由于一些历史遗留问题,现存的技术资料往往存在一些概念混淆、重复命名甚至自相矛盾之处。本文一来梳理 Skylake 微架构(主要是流水线)的组成和特性,二来试图厘清一些含混的概念用以帮助后来者。
另外在介绍完微架构之后,会继续结合 Perf 中的 Performance Event 来对照说明互为印证。
需要强调的是,本文的重点是Skylake的流水线(pipeline)架构,core间的连接和架构方式不作重点说明。
Skylake 介绍
Skylake 是由 Intel 以色列研发中心于2015年发布的 14nm CPU 架构。作为 Broadwell 的继任者,Skylake 在原有架构的基础上,对一些关键特性和组件做出了相当幅度的优化:
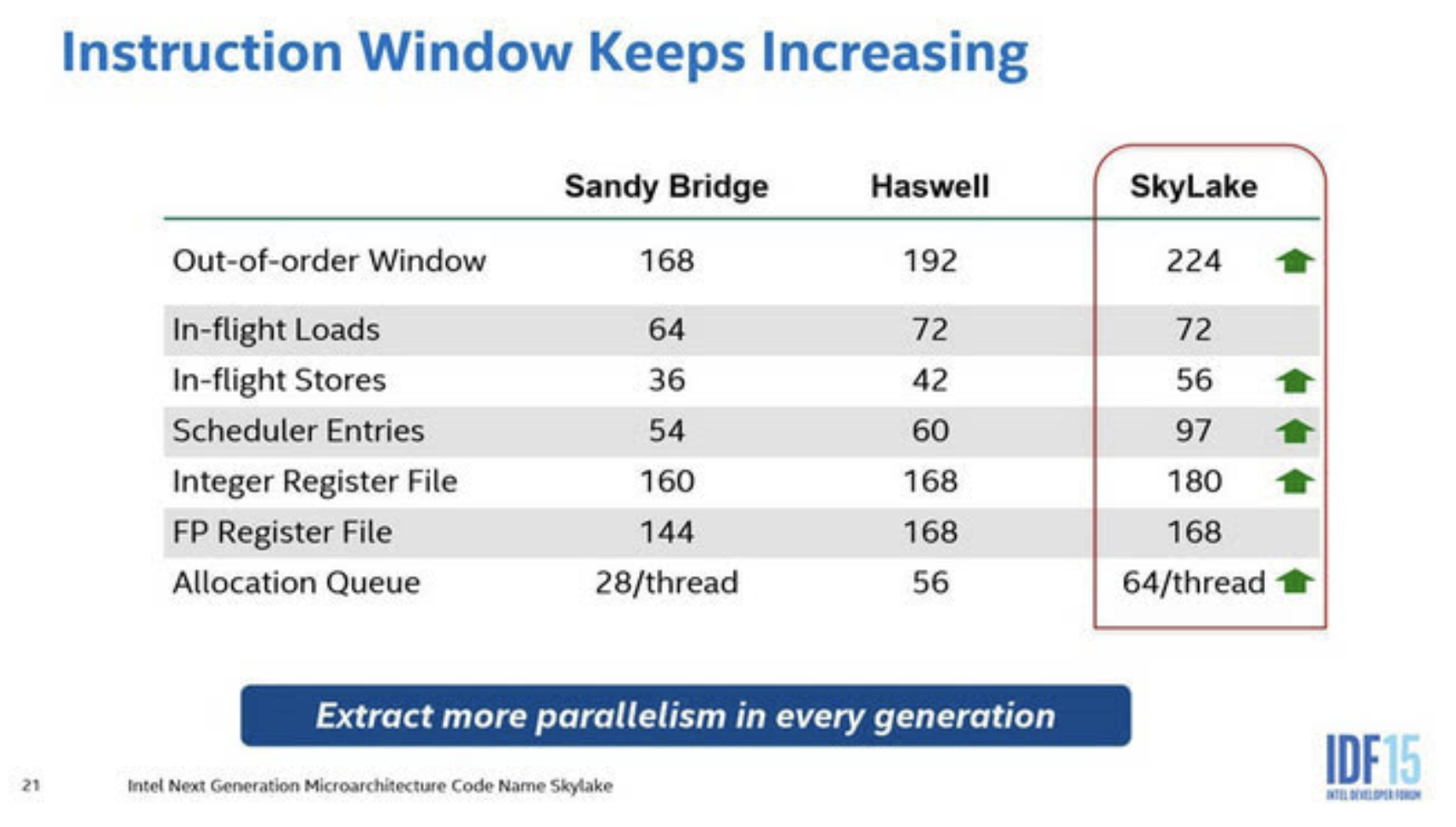
上图简单列举了一些量化指标,现在不求甚解就好。
在指令集方面,引入了AVX-512、CLFLUSHOPT、CLWB等新的指令集,不过本文不打算介绍这些东西,写到这里只是觉得如果只用上一段话结束这一小节有些太突兀了。
流水线概览
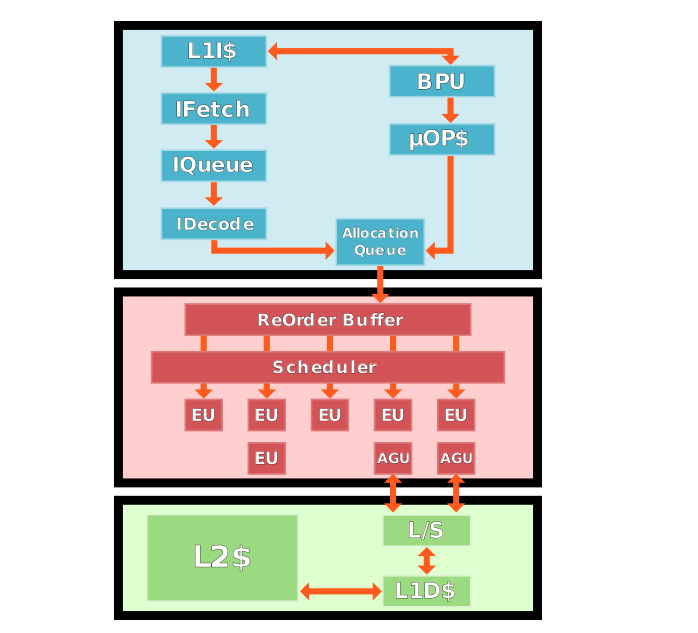
引用上面这张图是为了举一个反例,说明一下本文要解决的问题。这张图可以被当做是一张流水线的架构抽象,我可以指着每一个组件讲讲它们都是干嘛的,但这里的问题就是某一个相同的组件在不同的文档、资料、甚至语境下可能有两个甚至更多个名字。
比如蓝色方块最下面的Allocation Queue,它就还有一个名字叫做Instruction Decode Queue,同时它还有可能被叫做IDQ或AQ。而关于Decoded Instruction Queue、Micro Instruction Sequencer、Re-order buffer、Scheduler、Reservation Station等概念的辨析也是…需要下一番功夫。
本文将以全网最清晰的方式讲清楚这些概念。
从high-level的层面来讲,Skylake的流水线架构与Broadwell和Haswell没有太大出入。还是可以分为两个阶段:
前端(Front-End)
上图中蓝色部分就代表流水线的前端。它的主要作用就是获取指令、解码(Decode)指令。
为了最大限度的发挥CPU的能力,前端就需要尽可能高效率地把程序指令输送给后端。这里就面临两个挑战:
- 如何更快更准确地取得要执行的指令
- 如何将取得的指令更快地解码为微指令(micro-ops/uops)
有了更多的微指令输送给后端(执行单元),后端的工作量才能饱和。而前端的所有组件和机制,都是围绕这两个挑战进行的。
后端(Back-End)
上图中红色的部分就代表流水线的后端。一般来讲绿色的部分是存储子系统,虽然与后端交互,但严格讲不算在后端里面。
后端的主要任务就是执行前端送过来的指令。和前端类似,后端除了“来料加工”之外,也有它自己需要面对的挑战:
- 如何提高指令的并行程度
- 如何充分利用已有的CPU能力
如果将CPU比作一家餐厅,跑在上面的应用就是来餐厅就餐的食客。前端类似餐厅的服务生,需要接受客人的下单,同时将订单送到后厨。而后厨就类似后端,负责做出客人需要的菜品。
但如何能让上菜速度更快?前端是否可以在客人排位时就让其提前下单?后厨是否能够提前准备好本店热门的特色菜,或者一并煮好一大锅面条,根据需要浇上不同的浇头?
CPU说是高科技,其实干得也就是这些事情。
前端(Frontend)
处理器在前端这一部分的时候还是顺序(in-order)处理的,主要是也确实没什么乱序的空间。虽然说是顺序,但前端因为贴近业务,所以受人写的代码的影响也比较大。如果仅仅只是“取指令->解码”,恐怕需要写程序的人是个非常聪明的程序员。前端很多组件的工作其实都是在填程序员的坑,这也是我比较心疼前端的地方。
Fetch
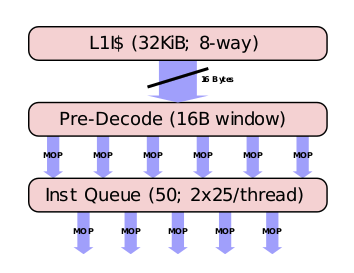
前端的任务,首先是从内存中取得指令。同读取数据类似,CPU 通过查询页表获得指令所在的内存地址,同时把指令塞到 CPU 的 L1 指令缓存里。
具体要把哪个地址上的指令数据送到 L1I$ 里,这是分支预测器(Branch predictor)的工作。作为 CPU 的核心技术,Intel 并没有透露太多信息,我们这里也只好一笔带过。不过它的细节也许很复杂,但它的脾气很好掌握:和我们很多人不喜欢自己的工作一样,它的工作就是处理分支,但它最不喜欢分支。
在 Skylake 架构里,L1I$ 大小为 32KB,组织形式为 8-way set associative (关于 CPU 缓存组织形式的讲解可以参照这篇),每个 Cycle 可以取 16Byte 长度(fetch window)的指令。如果你开了 Hyper-thread,那么同一个物理核上的两个逻辑核均分这个 fetch window,每个 Cycle各占用一次。
在 L1I$ 里的指令还都是变长的 x86 macro-ops,也就是我们看到的那些编译之后的汇编指令。如果熟悉这些指令的话,就会知道这些指令的长度(就是那些二进制数字)都不一样,同时一条指令有时可以由好几个操作组成。
这种指令对 CPU 的执行单元来说是很不友好的,同时如果想要通过乱序执行提高指令的并行度,减小指令的粒度也是必须的步骤。因此需要把这些marco-ops“解码”为 micro-ops。
当然具体的解码工作还在后面。从 L1I$ 中取得指令数据后,首先要进入“预解码”阶段,在这里需要识别出在一个 fetch window 中取得的这 16 个 Byte 的数据里面有多少个指令。除此之外,还需要对一些特殊指令,比如分支转跳打上一些标记。
但因为指令变长的原因,16 个 Byte 往往并不对应固定的指令数,还有可能最后一个指令有一半在这 16Byte 里,另一边还在后面。另外就是 pre-decode 在一个 Cycle 最多识别出 6 个指令,或者这 16Byte 的数据都解析完。如果你这 16 个 Byte 里包含有 7 个指令,那么第一个 Cycle 识别出前 6 个之后,还需要第二个 Cycle 识别最后一个,然后才能再读取后面 16Byte。
那么 pre-decode 的效率就变成了 3.5 instruction / cycle,比最理想的情况 6 instruction / cycle 降低了41%,现实就是这么残酷。
经过 pre-decode 之后,才真正从 16Byte 的二进制数据中识别出了指令,这些指令下一步要被塞到一个队列里(Instruction Queue)看看有没有什么能被优化的地方。一个最常见的优化方式就是macro-op fusion,就是把两个相邻的,且能被一个指令表示的指令,用那一个指令替换掉。比如:
1 | cmp eax, [mem] |
直接换成
1 | cmpjne eax, [mem], loop |
当然既然决定这么替换,新指令对流水线的开销肯定小于被替换的两个指令之和。如此可以减轻一部分后端执行单元的工作负荷和资源开销。
OK, 在取得了指令数据,识别出了数据中的指令,并对指令做了一些优化合并之后,就该开始正儿八经地解码了。
解码
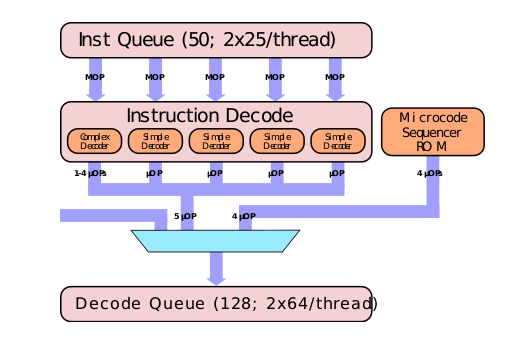
在拿到了经过“预解码”的macro-ops之后,开始正式进入解码过程。marco-ops进入 Instruction Decode 组件解码,最终的输出为定长的 micro-ops。
Insturction Decode 组件也有入口带宽限制,每个 Cycle 最多取 3 个 unfused 指令 + 2 个 fused 指令,或者 5 个 unfused 指令(这里指 macro ops)。所以说 fused 多了也不好,一个 Cycle 最多取两个。同时如果开了 Hyper Thread,则两个 Thread 按 Cycle 交替使用 Instruction Decode。
在 Instruction Decode 组件里面的就是各个具体的 Decoder。Decoder 类型可以分类两类,一类是 Simple Decoder,一类是 Complex Decoder,感觉这句是在说废话。
顾名思义,Simple Decoder 处理的是解码之后的输出为1个 fused-μop 的指令;Complex Decoder 处理的是解码之后的输出为1个至4个 fused-μop 的指令。
Fused-μop
注意这里说的是 fused-μop,不是 fused-marco。在这里所有输出的 μop 都是做过 fused 处理的,目的是减少后续资源的占用。
但这里有一个比较容易混淆的概念,就是
fused-μop并非专指那些两个μop合并之后生成的 “合并μop”,而是指所有经过了μop fusion处理的μop:有些指令可能两个μop变一个,但也有一些是一个还是一个,即便如此,输出的那一个也叫fused-μop。
为了进一步澄清这个概念,我们稍微需要涉及一点后端的概念。在前端这里,生成 fused-μop 的部分还属于 CPU 流水线中的 μops fused domain,而在后端需要将指令发射到执行单元去的时候,是不能执行 fused μop的,所以 fused μop 还需要再分解为 unfused μop才可以执行,这一部分就属于 CPU 流水线中的μops unfused domain。
有了这些概念之后,我们可以看一下Instruction Tables.pdf 这份文档。
在P244中有对 skylake 指令的说明,上面有对一些概念的解释,下面是一张表格:
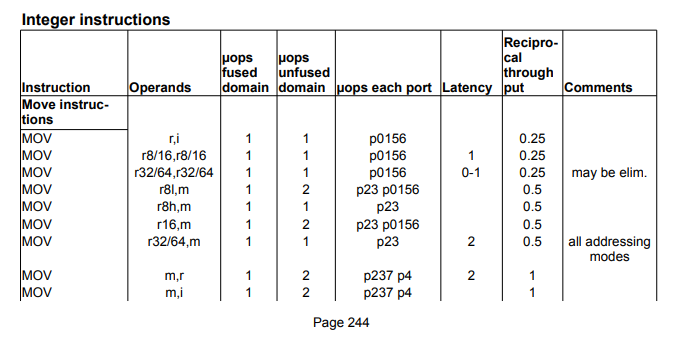
在这张表格里是最常见的 mov 命令的说明。但因为操作数(operands)的不同在真正执行的时候也会有细节上的差别。第一行中的 mov 的两个操作数一个是 register,另外一个是一个立即数。在 μops fused domain 和 μops unfused domain 两栏中的计数都是1。
这种指令也算在 μops fused domain 经过了 fusion 处理。只不过其实前后没什么区别。
但如果我们看一下所有在 μops unfused domain 里计数为 2 的 mov 指令,它们在 μops fused domain 中的计数都是 1。这种 mov 指令就是真正做过 2 条 μop合并的mov指令。
这份表格还有很多有趣的内容,推荐有时间的时候随手翻翻。
Skylake 有 4 个 Simple Decoder 和 1 个 Complex Decoder。但从表里我们可以看到 μopps fused domain 计数为1,也就是可以被 Simple Decoder 处理的指令在所有指令中所占的比例似乎并没有达到 4/5 那么高。
这里需要说明的是,输出大于 4 个 μop 的指令,既不由 Simple Decoder 处理,也不由 Complex Decoder 处理,而是直接去查 Microcode Sequencer(MS),这是一块类似于缓存的 ROM。
Complex Decoder 的数量始终为 1 的原因是 Complex Decoder 解码出来的 μop 都很难在执行时进行并行化处理,同时 Complex Decoder 每多解码一个 μop,就要有一个 Simple Decoder 处于不能工作的状态。
对 CPU 来说,它最希望的就是它要做的工作,它需要的数据,它要执行的指令,都已经在一块缓存里准备就绪了。这是 CPU 上班摸鱼的主要方法,但摸出了风格,摸出了水平。下一部分介绍一下在指令解码方面的缓存内容。
MSROM
MSROM(Micro-code sequencer ROM)就是在上文中提到的专门处理输出大于 4 个 μop的那块类似缓存的 ROM。很多文档里面也直接将其称为 MS,具体叫什么多需要结合上下文语境,知道是一回事就好了。
我个人其实推荐读者在编写自己的文档时能注意这些名称上的“一致性”,同编写程序时给变量或函数命名时的一致性一样,这些看似没什么“技术含量”的工作,却能够极大地提高信息传达的效率,也就是提高文档或代码的可读性和可维护性。
在 Instruction Decoder 收到一个输出要大于 4 个 μop 的指令之后,它就会将请求转发给 MSROM。MSROM 虽然是专门解码/查询大于 4 个 μop 的指令的组件,但它最大的传输效率是 4 μop/Cycle。同时在它工作的时候,所有的 Instruction Decoder 都要处于 Disable 的状态。因此虽然它的工作不太需要“动脑子”,但却仍要尽量避免。
Stack Engine
Stack Engine 是专门处理栈操作指令的专用组件。类似 PUSH、POP、CALL、RET 这样的指令都算栈操作指令。Stack Engine 不算什么新鲜的黑科技,自从Pentium M 时代起就已经出现在 Intel 的 CPU 中。它的主要目的是避免栈操作指令对后端资源的占用,从而为其他计算任务提供出更多的资源。为此,Stack Engine 提供栈操作指令专用的加法器和其他所需的逻辑完成这一任务。
Stack Engine 在 Instruction Decoder 之后,监控所有流出的 μop,并且从中提取出栈操作指令,进而直接执行,从而减轻栈操作指令对后端资源的占用。
这也可能是为什么有些时候 inline 的函数性能还不如不 inline 的原因吧:D(不负责任猜测
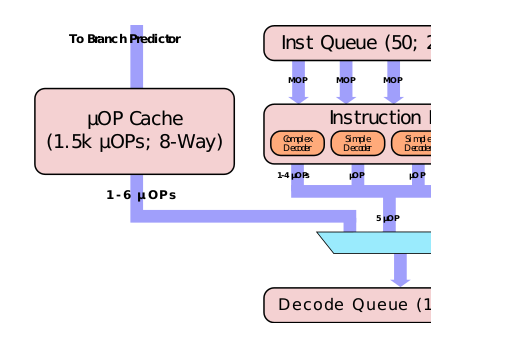
Decoded Stream Buffer(DSB)
别名
像 DSB 这种组件,首先要说明的就是它也叫 μop cache 或 decoded icache。
作用
无论是用 Instruction Decoder 还是用 MSROM,终究还是要做一次 “解码” 的操作。但同所有 Cache 加速的原理一样,如果能把解码之后的结果(μop)存下来,下次再出现的时候直接使用,那么就可以显著提高解码速度,DSB 就是这个目的。
参数
DSB 的组织形式是 32 个 set,每个 set 有 8 条 cache line,每条 cache line 最多保存 6 个 μop。
每次 cache hit 可以传输最大 6 个 μop/Cycle,这 6 个 μop 最大可以对应到 64 byte 的前端 fetch window size,并且完全不需要任何 Instruction decoder 参与,也没有繁琐的解码过程。在实际应用中,DSB 的 cache hit rate 在 80% 或以上。
与icache的关系
CPU 的 icache 一般存储的是最原始的从内存里读进来的程序的汇编指令(marco instruction)。而 DSB 或者 μop cache 虽然也是存 instruction 的 cache,但如前所述,它存的是已经解码好的 μop,所以这玩意有时候又被称为 “decoded icache”。当然了,这些 μop 都是 CPU 的 icache 中的指令解码之后得到的。
与MSROM的关系
输出大于 4 个 μop 的指令依然只能由 MSROM 解码。DSB 保存的也是那些小于等于 4 个 μop 指令的 μop。
MITE Path和DSB Path
这两个概念主要用于区分最终需要执行的 μop 是通过什么方式来的。在上一节 Decoded Stream Buffer 之前的所有内容,都算是 MITE Path。MITE 是(Micro-instruction Translation Engine)的缩写,同时它在有些文档里也被称作 legacy decode pipeline 或 legacy path。这条线路上过来的 μop 都是从 marco instruction 一步一步解码来的。
DSB path 就是直接从 DSB 那条道上过来的 μop。当 CPU 需要在 MITE Path、DSB Path 以及 MSROM 之间切换(switch)以便取得所需的 μop 时,需要花费一定的 CPU Cycle 完成这一工作。
Instruction Decode Queue(IDQ)
IDQ 也叫 Allocation Queue(AQ),也有时候会写成是 Decode Queue。解码完成的 μop 在进入后端之前需要先在 IDQ 中做一下缓冲。作为一个 ”缓冲队列”,主要作用是将前端解码可能引入的流水线”气泡(bubbles)“消化掉,为后端提供稳定的 μop 供应(目标是 6μop/Cycle)。
Skylake 的 IDQ 最大可以存放 64 个 μop/thread,比 Broadwell 的 28 个多一倍还多。这些 μop 在 IDQ 中除了排一下队之外,还会被 Loop Stream Detector(LSD)扫描一遍,用来发现这些 μop 是不是来自于一个循环。
Loop Stream Detector(LSD)
如果在 IDQ 中能被发现存在循环体 μop,那么在下一次循环的时候,就不需要去重新解码这些循环体生成的 μop,而是直接由 LSD 提供 μops。这便可以省去指令 fetch、解码、读 μop cache、分支预测等所有之前的步骤,并且能进一步减少缓存占用。当然,当 LSD 起作用的时候,整个前端都是处于 Disabled 的状态。
Skylake 的 LSD 需要在 IDQ 的长度(64μop)内发现循环,所以,循环体还是尽量紧凑一点吧:D
后端 (Backend)
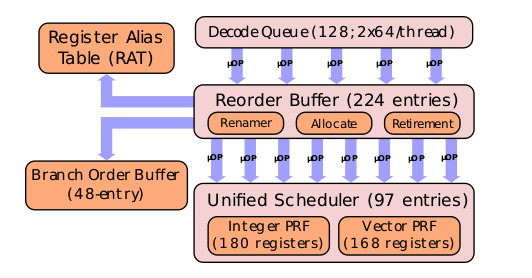
还是首先介绍一下这个部分是否有别的名字。在有些文档里后端又直接被称为 Execution Engine。后端的主要任务当然就是执行前端解码出来的这些 μop。但后端和前端的设计都在围绕着“如何提高指令的并行性”来设计和优化。
在 Skylake 架构中,IDQ 以最大 6μop/Cycle 的速度将 μop 送入 Re-order Buffer,后端的处理在 Re-order Buffer 中正式开始。
Out-of-order(OOO)Execution/Engine
先讲一下OOO(乱序)以便对后端的执行有一个整体的把握。
我们的程序虽然是按顺序编写的指令,但CPU并不(一定)会按相同的方式执行。为了提升整体效率,CPU采用的是乱序执行的方式。从一个“窗口”范围内选取可以执行的指令执行,并且这些操作对用户透明,在程序编写者的角度看来仍是在按他编写的指令顺序执行。
从根本上来讲,OOO是用”数据流(Data flow)”的角度来看待程序,而非程序员的“指令流”视角。
指令的目的就是以一种特定的方式操纵存在于内存/缓存中的数据,引起数据的变化,其实这就是我们通常所说的“写程序”。只不过这是人类习惯的逻辑方式,在机器看来并不一定高效。
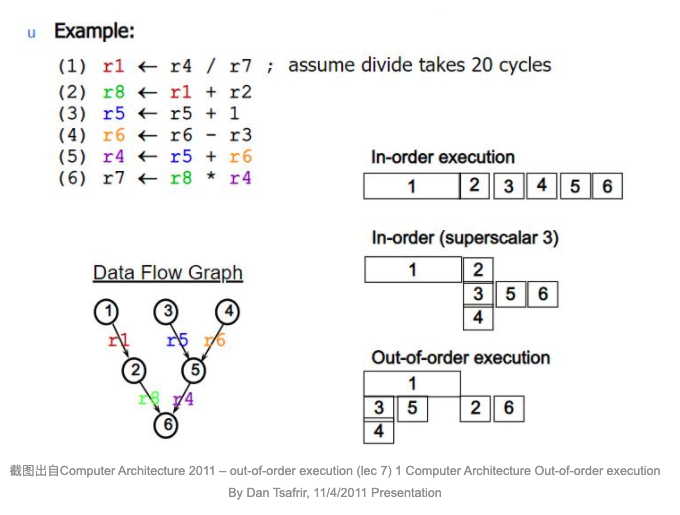
在上图例子中,需要执行左上角的六个计算指令。In-order execution 是假设完全按照程序顺序执行这六个指令的耗时。下面的In-order(superscalar3) 是合并了一些可以并行执行的指令的耗时。
因为指令(2)中的 r1 要依赖指令(1)的结果,所以指令(2)只能等(1)执行结束再执行。而本来可以并行执行的(3)(4)也因为要保证 In-order 顺序而只能一同放在(1)之后执行。
但从左下角的 Data flow 的角度来看,其实我们并不需要按照指令顺序运行程序:指令(2)完全可以放在后面执行,并重新安排并行计算顺序。这样就又节省了执行所需的时间。
OOO选择可执行指令的依据是:
- 不依赖未执行指令操纵的数据
- 有可用的执行资源
为了尽可能让进入后端的指令满足这两个条件,OOO采用了一系列的组件和技术。在后面的章节中将会进行介绍。
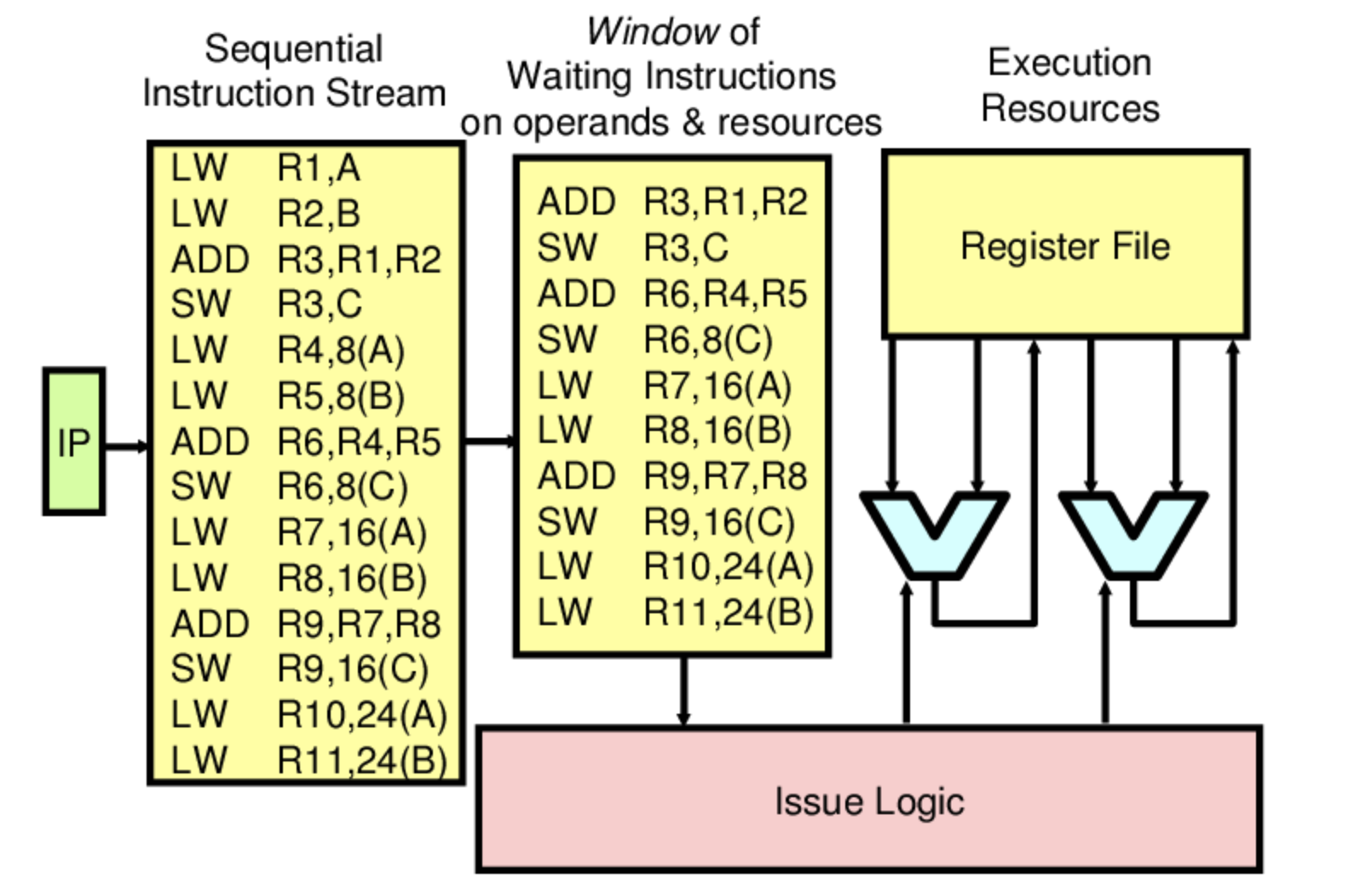
上图是一个OOO的概念示意图。前端输出给后端的都是顺序指令流,后端在一个窗口范围中选择可以执行的指令进行乱序执行。这里面没有强调的是,最终指令退出(retire)的顺序仍是按照程序的顺序。
OOO Once More
这里对 OOO(Out-Of-Order) 乱序执行再简单讲两句。深入乱序执行的难点不在于“不按指令顺序执行”,而是如何做到“按指令顺序退出”。
这里面的关键是,所有执行过的指令都先被“缓存”起来,并不把执行之后的结果真正写到寄存器或者内存里。从用户角度看,这个指令其实并没有被“执行”,因为它没有引起任何数据方面的变化。等到它可以确定是需要被执行的指令,并且它前面的指令都已经把结果写入(commit)之后,它再去 Commit。这样从用户角度看来,程序就是按照指令顺序执行了。
在很多文档里,
Commit和Retire是两个可以互换(interchangable)的词。
说实话,研究这块东西,最烦的就是同一个概念有N个名字。
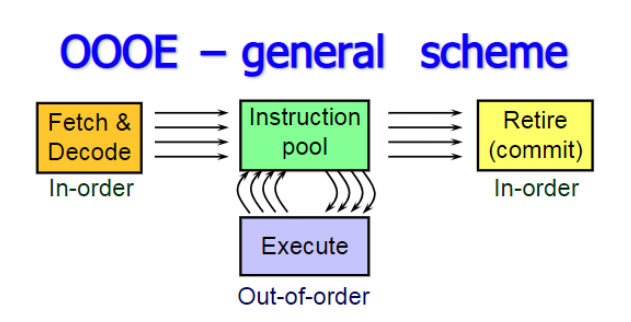
再来总结一下 OOO 的 Big Picture :
- 左边
Fetch&Decode是之前讲的前端(Front-End)相关的内容。此时指令还是有序的。 Decode成微指令(μop)之后,这些微指令进入一个指令池(Instruction Pool),这里面能够被执行的指令,就直接被执行。“能够被执行”是指满足以下两个条件:- 已有指令需要的数据
- 执行单元有空闲
- 当指令被执行之后
- 通知所有对该指令有依赖的指令(们),它们所需要的数据已经准备好。
- 注意这里说的是“执行”,不是上面说的 “Retire” 或 “Commit”
- 为实现这一功能,CPU 中还必须要对微指令的操作数(数据)有 Bookkeeping 的能力
- Commit 指令
- 只有当前指令的前序(指令顺序)指令都 Commit 之后,才能 Commit 当前指令
- Commit 也可以并行进行,前提是满足上面一条的条件,同时并行 Commit 的指令间没有依赖
False Dependency
乱序执行的一大前置条件就是指令数据间没有相互依赖。下面就着重分析一下依赖。
用下面的指令过程作一个示例:

简单分析一下:
- Read After Write(RAW) 型依赖
(2)指令需要读取r1的值,而r1的值需要(1)指令执行之后给出。所以(2)指令对(1)指令有 RAW 依赖。RAW 依赖也被称作true dependency或者flow dependency。 - Write After Read(WAR) 型依赖
(3)指令需要更新r8的值,但在此之前(2)指令需要读取r8的值参与计算。所以(3)指令对(2)指令有 WAR 依赖。WAR 依赖也被称作anti-dependencies。 - Write After Write(WAW) 型依赖
(4)指令需要在(2)指令写入r3之后再写入r3。所以(4)指令对(2)指令有 WAW 依赖。WAW 依赖也可以被叫做output dependencies
按照以上的分析,这几条指令几乎没有可以并行执行的余地。不过,我想你也已经看出了一些“转机”:针对WAR和WAW,是可以被Register Rename这种方法破解的。这两种依赖都被称为 false dependency。
Register Rename
当需要写入 r1 的指令在读取 r1 的指令之后,写入的 r1 的新值可以首先保存在另外一个寄存器 r1’里。读取 r1 的指令仍然读取原 r1 寄存器中的值,这样WAR 指令就可以并行执行。当所有需要读取 r1 原值的指令都执行完毕,r1 就可以用新值代替。
Register Rename其实就是利用CPU提供的大量的物理寄存器,为寄存器制作“分身”或者,Alias,提供能够增加程序并行性的便利。
上面的例子里,r1 是 architectural register,r1’ 是内部的 physical register。Rigster Rename 就是在制作这两种寄存器间的映射关系。当然,这一切对用户来说都是透明的。
如前所述,physical register 的数量远多于 architectural register 的数量。其实 architectural register 仅仅是一个“代号”,并不是真正存放数据的位置。用这种方式,可以消除 WAW 和 WAR 这两种数据依赖进而增加程序整体的并行性。
那么到底怎么操作呢?其实本质上也就是建立一个“映射表”,一个从“代号”到存储位置的映射表。
E.g.
现有5个 architectural register 寄存器:r1, r2, r3, r4, r5;9个 physical register 寄存器:p1, p2, …, p9。
指令:
1 | Add r1, r2, r3 ;r1 = r2 + r3 |
最开始是一个简单的映射关系:
| r1 | r2 | r3 | r4 | r5 |
|---|---|---|---|---|
| p1 | p2 | p3 | p4 | p5 |
在这张表里面还有一个 FreeList,用来保存还没有被占用的 physical register。
| p6 | p7 | p8 | p9 |
OK,首先考虑不使用 Register Rename 的情景。第二条指令是必须等待第一条指令执行完成之后才能执行,因为 r1 有 RAW 型依赖。这个其实 Register Rename 也没有办法。但是第三条指令也不能在第二条指令之前执行,因为写入 r1 可能会影响第二条指令的结果(r2)。
为了增加指令的并行性,让第三条指令能与第一条指令并行,同时消除 WAW 和 WAR 型依赖,看一下 Register Rename 是怎么做的。
第一条指令就用原始对应的寄存器,此时还没有 Register Rename。对应的“映射表”Rename Table如下:
| r1 | p1 |
| r2 | p2 |
| r3 | p3 |
| r4 | p4 |
| r5 | p5 |
第二条指令中,r2 针对第一条指令有 WAR 型依赖,可以将写入 r2 的结果放在另外一个寄存器里。从 FreeList 中选取下一个空闲的 physical register,即 p6。
所以这条指令实际上就变成了Sub r6, r1, r2; r6 = r1 - r2。
Rename Table如下:
| r1 | p1 |
| r2 | p6 |
| r3 | p3 |
| r4 | p4 |
| r5 | p5 |
即告之后续指令 r2 最终的结果保存在 p6 里面。
第三条指令,r1 针对第一条指令有 WAW 型依赖,可以将写入 r1 的结果放到另外一个寄存器里。从 FreeList 中选取下一个空闲的 physical register,即 p7。
所以这条指令实际上就变成了 Add p7, p4, p5 ; p7 = p4 + p5
Rename Table 如下:
| r1 | p7 |
| r2 | p6 |
| r3 | p3 |
| r4 | p4 |
| r5 | p5 |
即告之 r1 最终的结果保存在 p7 里面。
所有指令对
architectural register的读取都先通过Rename Table获得确切地址。
回到最初提到的问题,因为第一条指令和第三条指令实际写入的寄存器(分别是p1和p7)并不冲突,且第二条指令仅在 p1 中读取数据,因此这两条指令可以并行执行。
现代CPU的 Rename Table 一般是在 ROB 里的 RAT(Rename Alias Table)。同时 physical register 也会被 ROB entry 取代。
其实现在对 Register Rename 的理解更多的是建立一个概念,在整个微架构中,这一步不是一个孤立的组件,所有组件之间都需要紧密配合。
后续会对后端的执行进行示例介绍。
示例
一个示例介绍Reorder Buffer(ROB)和Register Alias Table(RAT)和Reservation Station(RS)
理解乱序执行(Out-of-Order)的核心其实就是把ROB,RAT和RS这三个组件搞透。
如果要单独讲,很容易成为一大锅概念和专有名词的杂烩。所以这次把这几个紧密相关的组件放到一起,先用例子说明,仅描述自然行为,同时也避免出现太多概念。
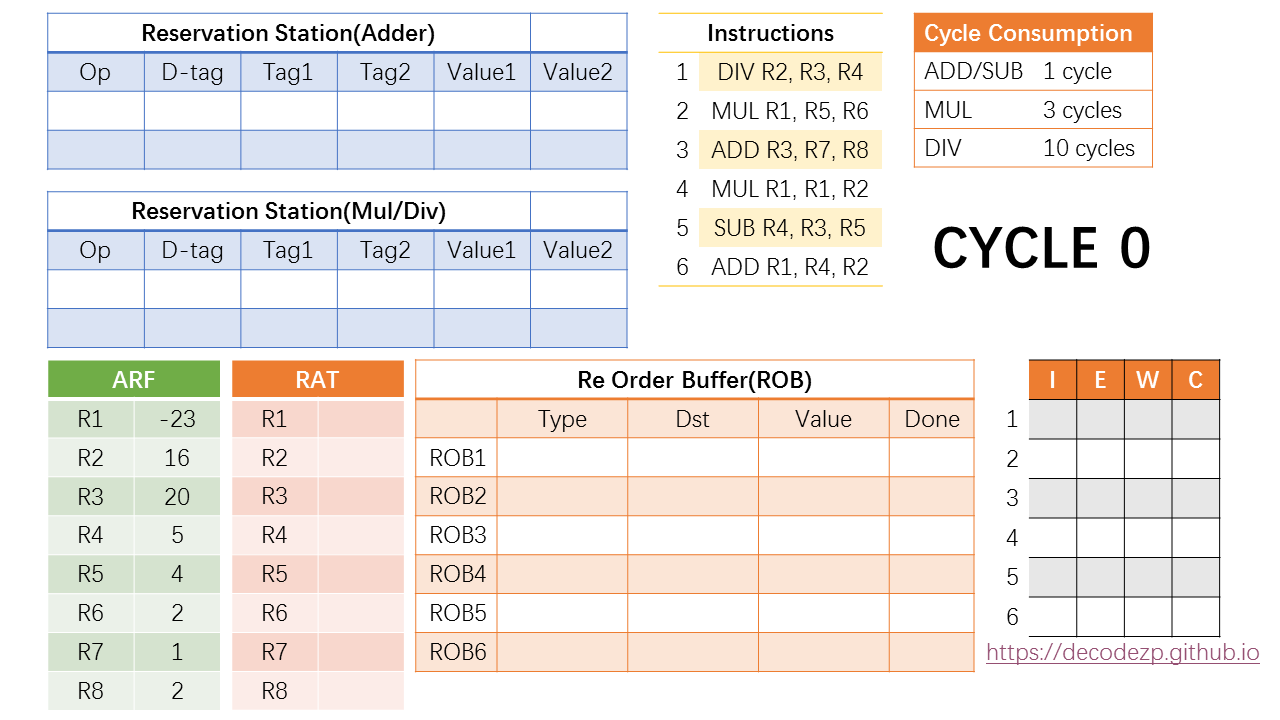
上图是在一个起始时刻 CYCLE 0 时CPU后端各组件的状态。它即将执行 Instructions 表格里的6条指令。不同种类指令所需要消耗的执行时间如 Cycle Consumption 所示。
ARF 是 Architectural Register File,里面保存有当前时刻 architectural register 中的值;RAT 就是前面介绍过的 Register Alias Table,主要用作对 architectural register 的Rename。
Reservation Station(RS) 根据所连接的执行不同类型指令的Port而分成两类,一类保存 ADD/SUB 相关的指令,一类保存 MUL/DIV 相关的指令。里面的指令在两个Value都 Ready 的时候将发送到执行单元执行。
Re Order Buffer 旁边的表格是这6条指令从 Issue 到 Execute, Write 最后再到 Commit 这几个状态的 cycle 时刻表。
OK,那么下面进入第一个cycle。
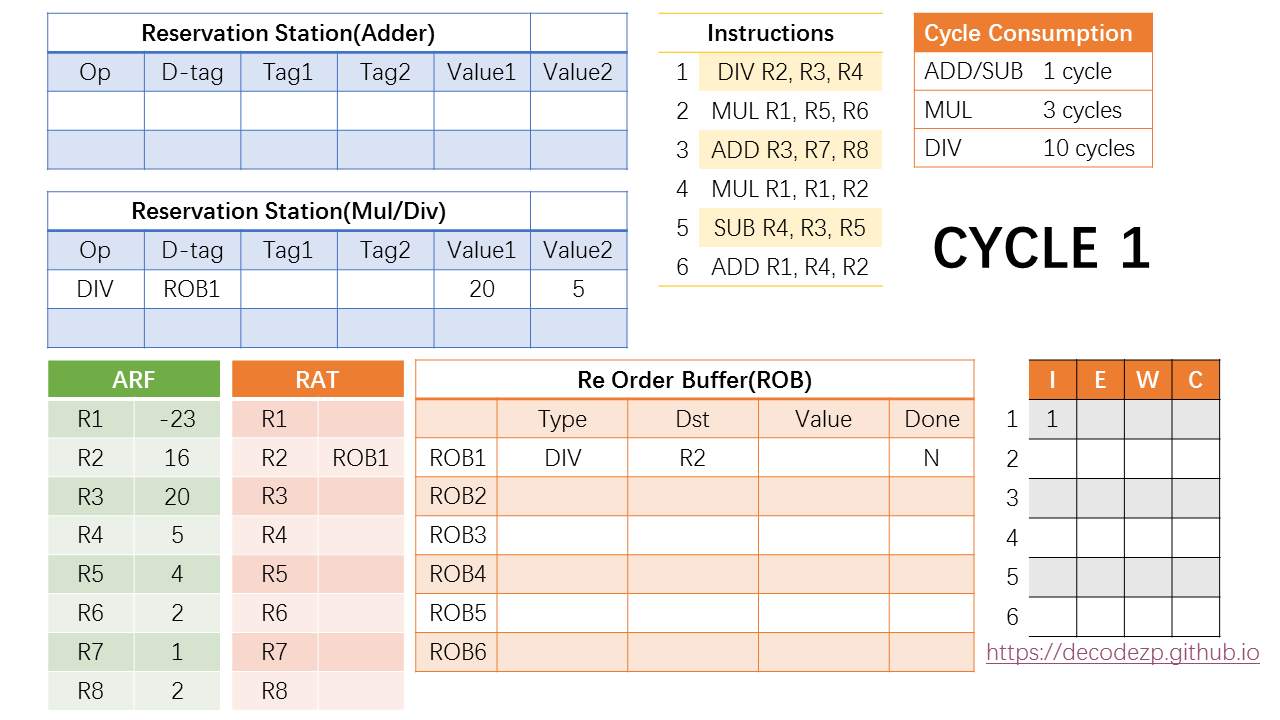
第一条指令 DIV R2, R3, R4 按照先进先出的原则首先进入 ROB1。
在ROB中,Dst 填该指令的目的 architectural register,也就是 R2;Value 是该指令执行完计算出来的结果,显然现在还不得而知,表示是否执行完的Done 标志位也是N的状态。
同时针对 DIV 指令的RS中也有空闲资源,因此该指令也会在同一cycle进入RS。目的 tagD-tag 填写指令对应的 ROB 条目(ROB1);Tag1 和 Tag2 通过查阅 RAT 中 R3 和 R4 的状态,如果有 Rename 的情况,则填写对应的 ROB 条目,如果没有,则直接读取 ARF 中的值,作为 Value 填入。
因此,D-tag 是 ROB1,Tag1 和 Tag2 因为 R3 和 R4 没有 Rename 所以不填,直接读取 ARF 中的值,20 和 5,放入 Value1 和 Value2 中。
之后,在 RAT 中,R2 被 Rename 成了 ROB1,即表示后续指令欲读取 R2 的值的话,都应该去读取 ROB1 中 value 的值。
此时该 DIV 指令所需要的操作数都已经 Ready,那么就可以在下一个 cycle 时从 RS 中 发射 到执行单元去执行。
下面进入第二个 cycle。
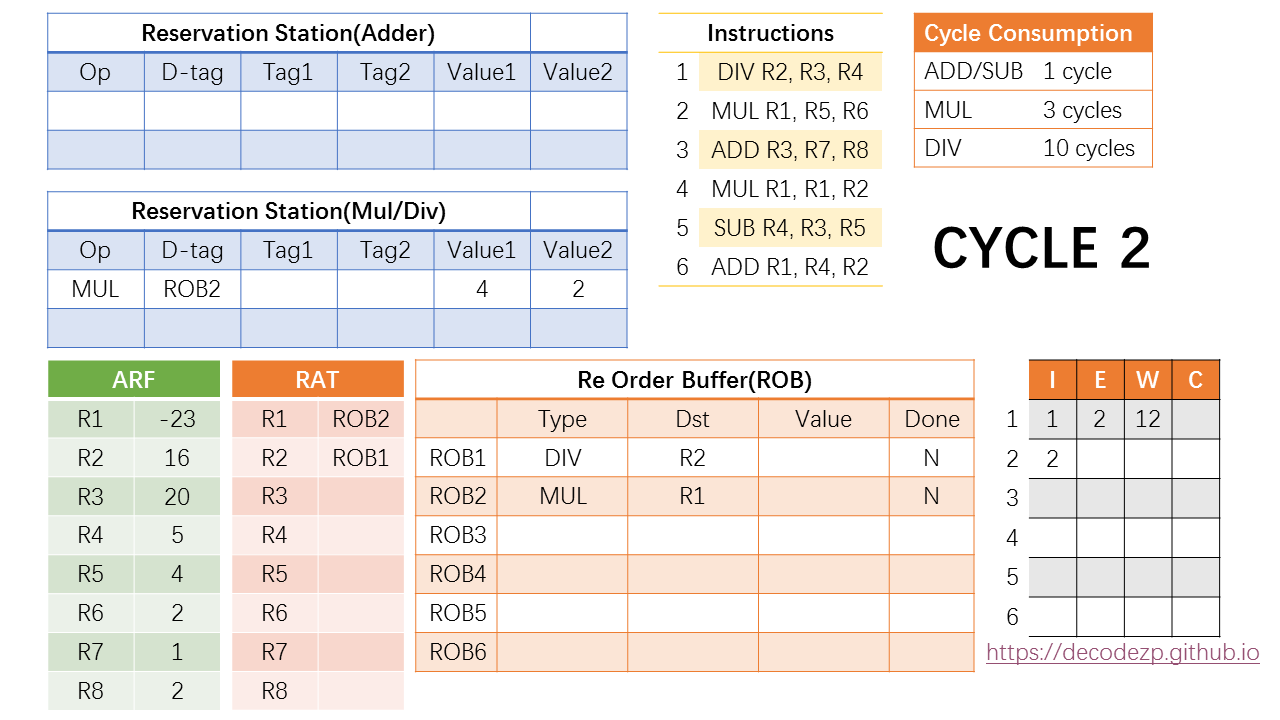
在第二个 cycle 中,第一条 DIV 指令开始执行,根据 DIV 的执行周期,那么我们知道它将在第 2 + 10 = 12 个 cycle 中执行完成。同时 ROB 中还有空闲,我们可以 issue 第二条 MUL 指令。
在 RS 中,上一条 DIV 指令已经清出,也有空闲资源,所以 MUL 指令也可以进入到 RS 中。另外几个选项也如 DIV 指令的判断方式,因此 D-tag 为 ROB2,两个 value 为 4 和 2。此时 MUL 指令也已经 Ready,可以在下一 个cycle 开始执行。
同时 RAT 中将 R1 rename 到 ROB2。因为后续最新的 R1 的值将等于 ROB2 中的 value。
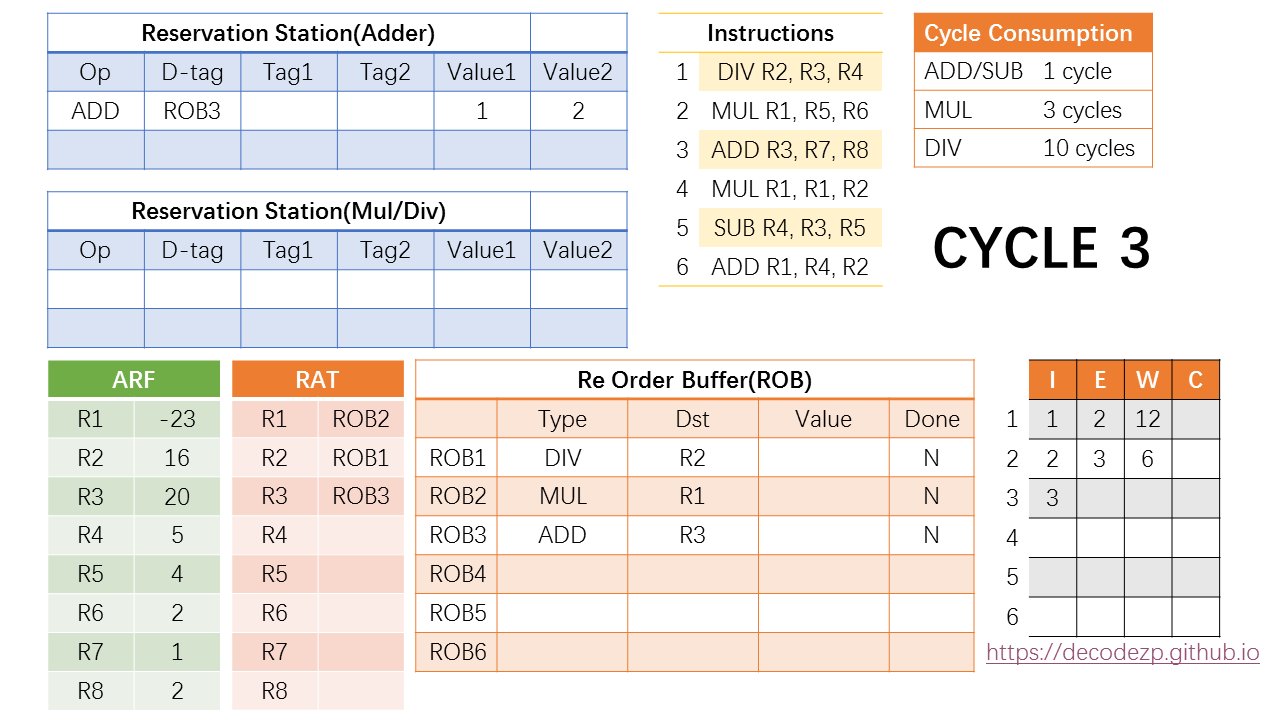
在第三个 cycle 中,MUL 指令开始执行,根据 MUL 的执行周期,它将在第 3 + 3 = 6 个 cycle 中执行完成。因 ROB 中还有空闲,此时可以 issue 第三条 ADD 指令。
RS 里面,ADD 指令需要放到存放 ADD/SUB 指令的 RS 中,除此之外,各字段的填写方式与之前的指令没有区别。R7 和 R8 也可以直接从 ARF 中获取数值,因此该 ADD 指令也已经 Ready,可以在下一个 cycle 开始执行。
之后,RAT 中将 R3 rename 到 ROB3。
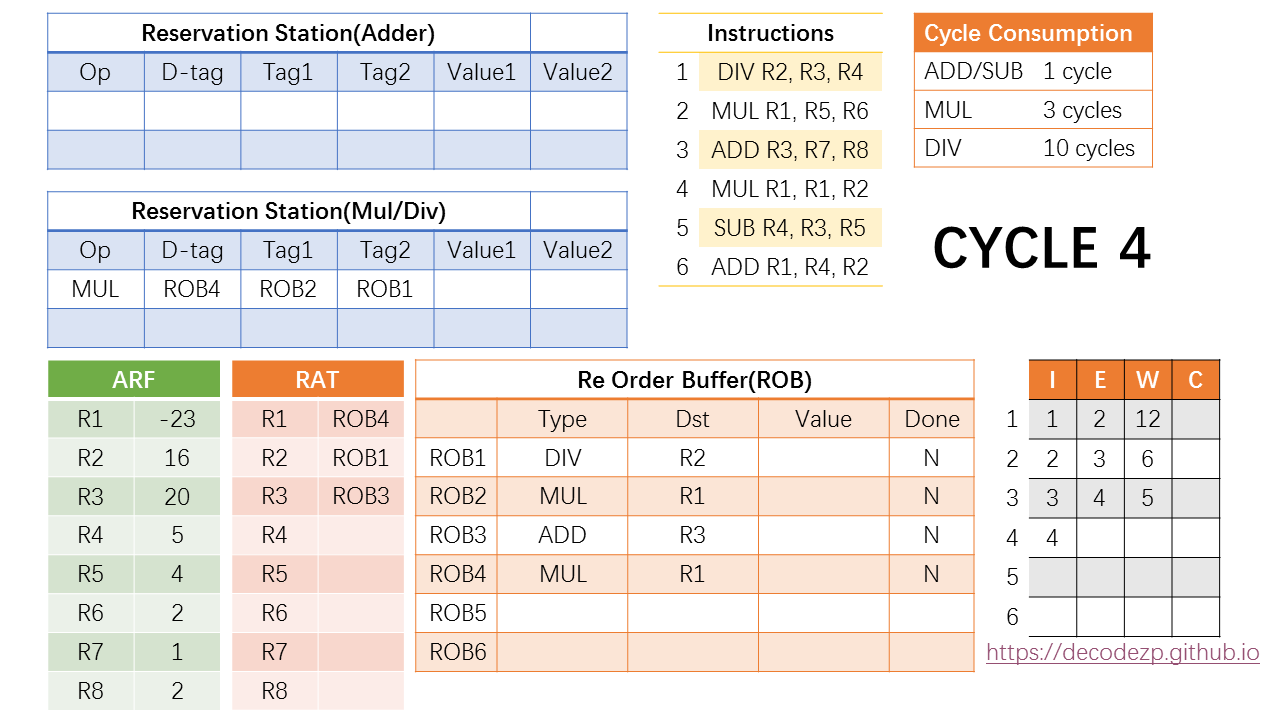
那么在第四个 cycle 中,第四条 MUL 指令可以进入 ROB 和 RS 之中。在 RS 中,D-tag 填入该指令对应的 ROB 条目,即 ROB4。而它的第一个操作数 R1 通过RAT 读取(参见 cycle 3 中的 RAT 情况。),rename 到了 ROB2,因此 tag1 需要填 ROB2。Tag2 同理,填 ROB1。
之后,RAT 中的 R1 需要 rename 到 ROB4,以保持最新的状态。
RS 中,因为该条指令两个操作数的 value 还没有 Ready,不能在下一个 cycle 开始执行,因此还暂存在 RS 之中。
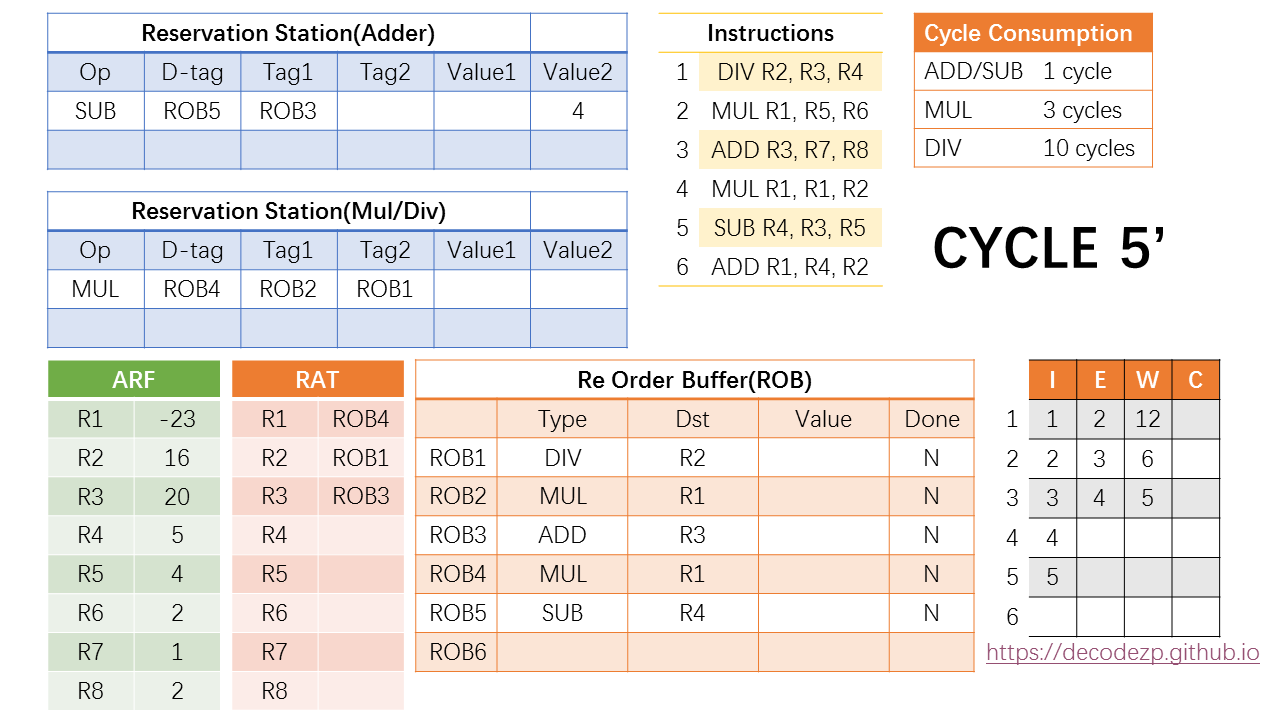
在第五个 cycle 中,拆成两个阶段来看。第一个阶段,也即 cycle 5',第五条 SUB 指令进入 ROB 和 RS,各字段的填写方式与之前相同。
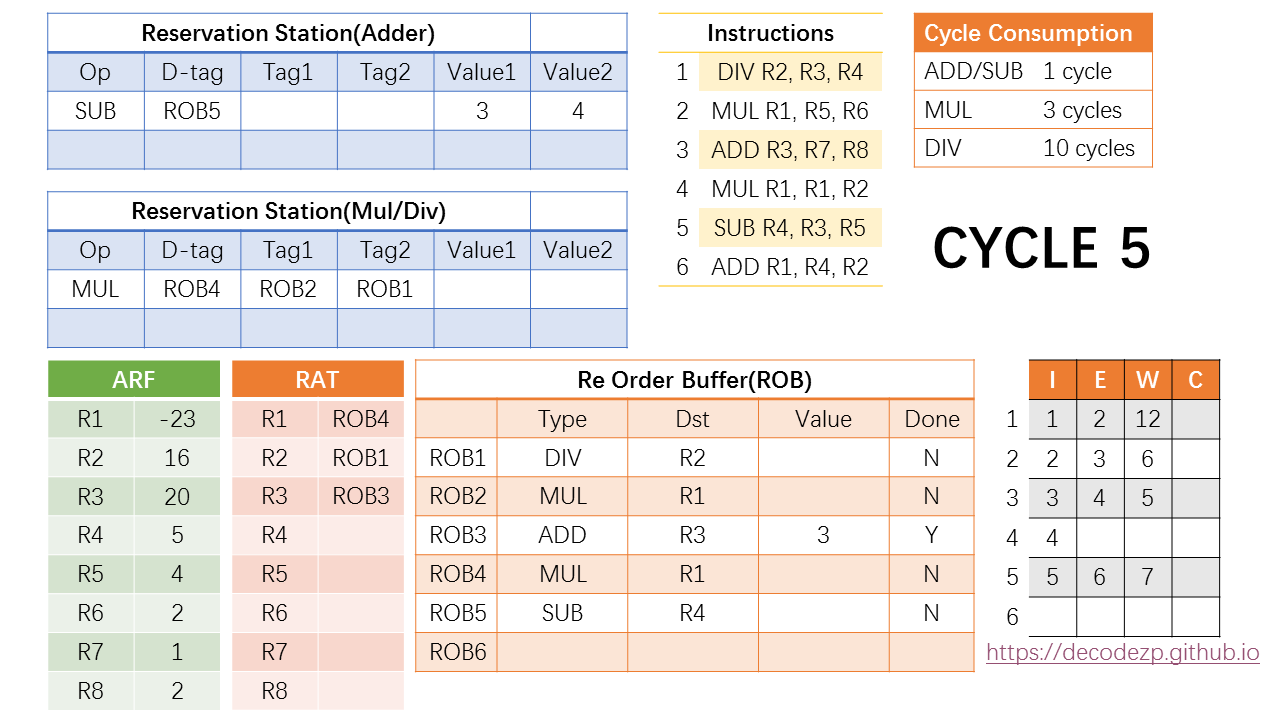
在 cycle 5 的第二个阶段中,注意到指令时刻表中,第三条在指令将在 cycle 5 完成执行,并进入 Write 阶段。
于是此时第三条指令在 ROB 中对应的 ROB3 的 Value 中将填入该指令执行的结果,也就是 3,同时设置标志位 DONE 为 Y。
在执行完成之后,在同一个 cycle 中,CPU 还将进行一个操作,就是将该结果广播给 RS 中现存的指令,如果有等待 ROB3 执行结果的指令,将接收该结果并更新状态。
在当前 RS(Adder) 中,SUB 指令正在等待 ROB3 的结果(参见cycle5'),于是其不再等待 Tag1,并在 Value1 中填入结果 3。此时该 SUB 指令也已经 Ready,并将在下一个 cycle 中执行,根据其执行开销,将在第 6 + 1 = 7 cycle 时执行完成。
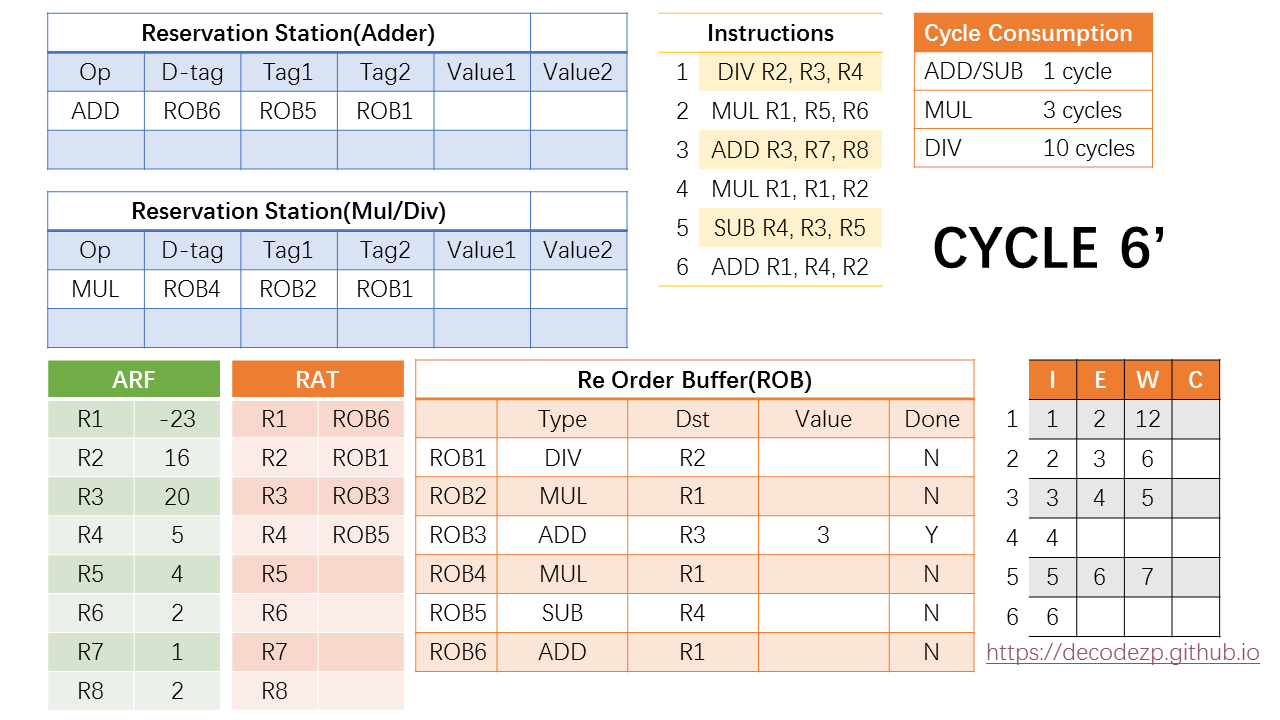
第六个 cycle 仍然分为两个阶段。第一个阶段 cycle 6’ 里,第六条 ADD 指令指令可以进入 ROB 以及 RS。
在 RS 中,D-tag 填写该指令所在的 ROB 条目 ROB6,两个操作数通过读取 RAT 获得,R4 和 R2 对应的分别是 ROB5 和 ROB1。
RAT 中 R1 所对应的最新值修改为 ROB6。
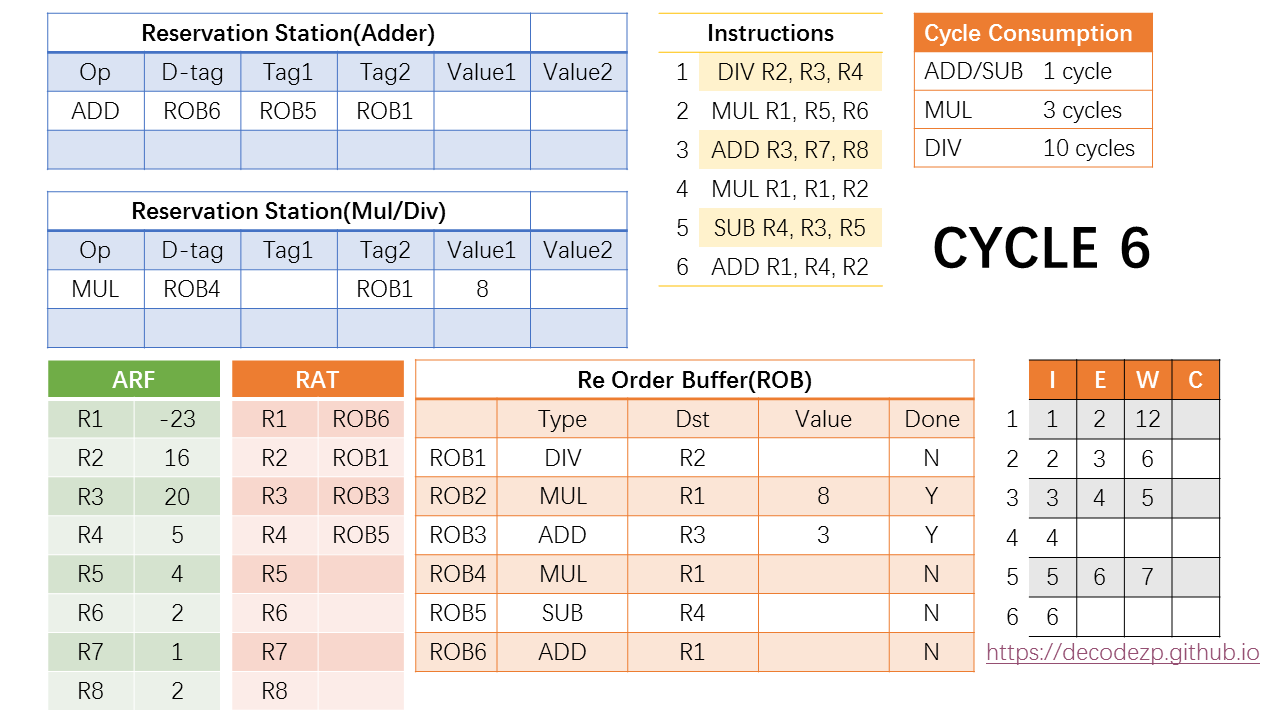
在第二个阶段,注意到此时第二条指令也在 cycle 6 执行完毕,因此它将执行的结果(8)写入到其所在的 ROB 条目 ROB2,并在同时将执行的结果广播给 RS 中的指令。
此时 RS 中的 MUL 指令正在等待 ROB2 的值,此时将其对应的 Value1 中写入计算的结果(8)。
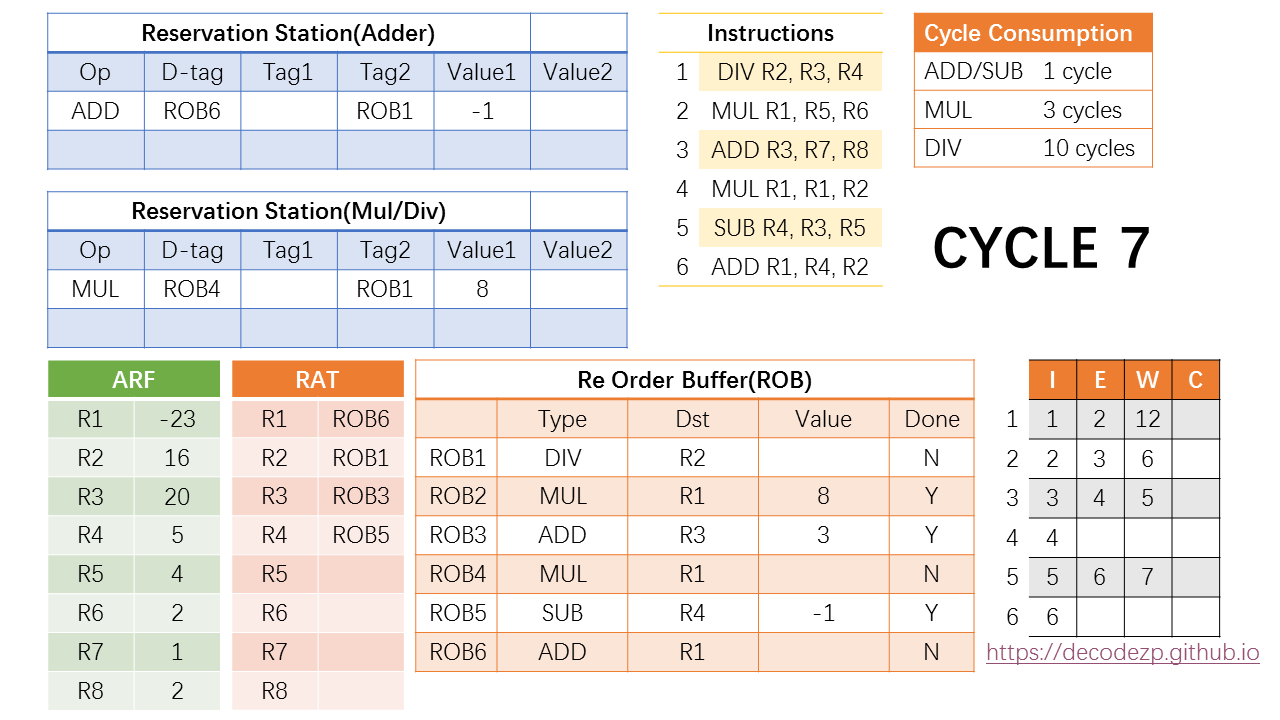
在第七个周期,注意到第五条指令也该执行完成,其所执行所得到的结果(-1),也需要写回到 ROB5 并广播给 RS 中的指令。但此时没有等待该值的指令。所以对其他状态暂时没有影响。
但如果此时有新的指令需要 R4,ROB5 此时的值可以直接传递给该指令。
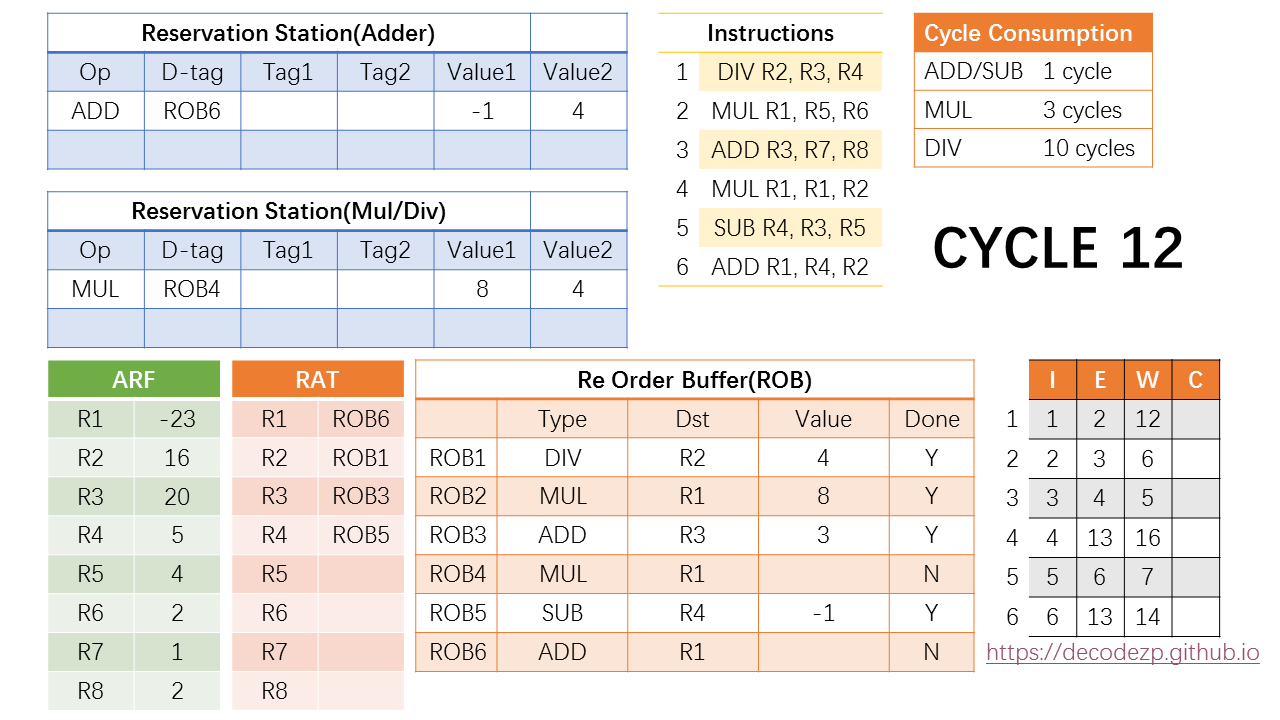
在第 7 个指令之后,CPU 进入一个尴尬的时期。没有新的指令执行完毕,RS 中的指令也没有 Ready 的,观察一下时刻表,下一个时刻有新的指令执行完毕是 cycle 12 的事。
在 cycle 12 中第一条 DIV 指令执行完毕,结果写入 ROB1,广播结果给 RS 中的指令,正好两个都需要 ROB1,并且拿到这个结果之后都进入 Ready 状态,可以在下一个 cycle 执行。
更新一下第四条和第六条指令的时刻表,执行都是在第13个 cycle,完成将分别在第 16 和 14 个cycle。
此时还发生了一件事,就是 ROB 中的第一条指令的 DONE 标志位标成了 Y。ROB 之前我们介绍是一个先入先出的 FIFO 结构,只有第一条指令完成之后,才能按顺序开始 commit。
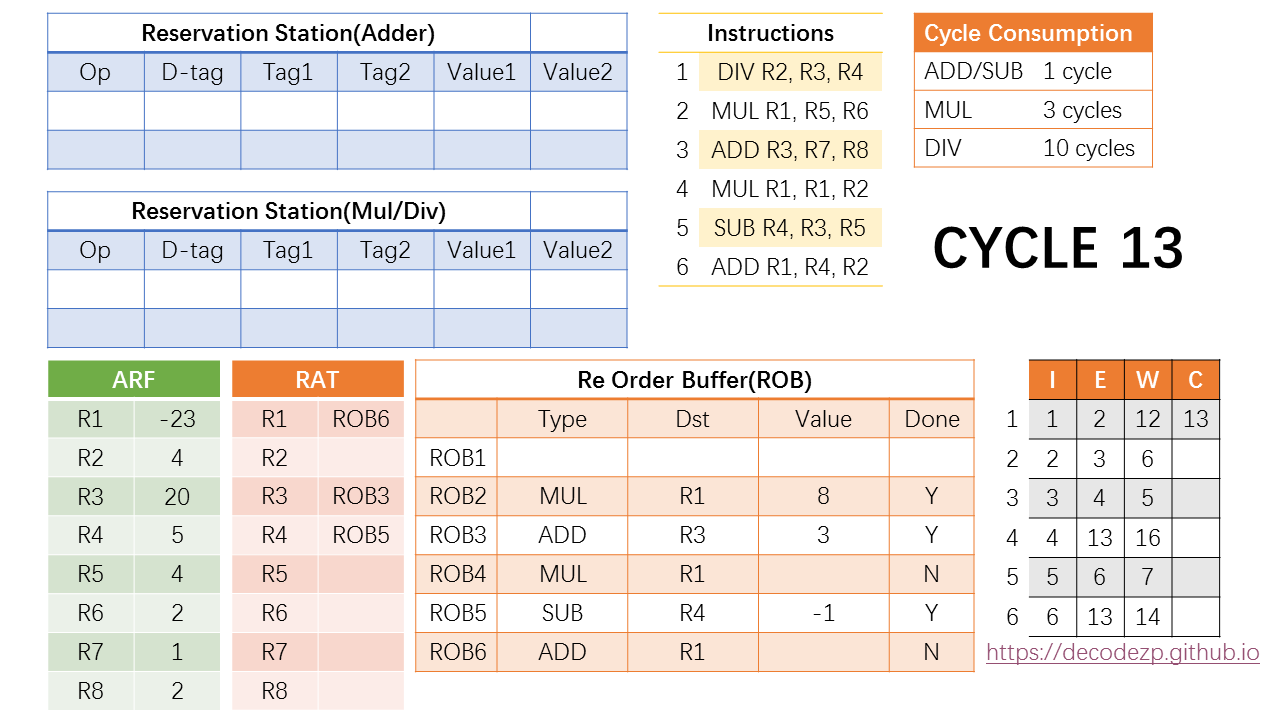
所以在 cycle 13,第一条指令历史性的 commit 了。Commit 的意思就是把结果写入到 ARF,因此 R2 在 ARF 中改为了4。同时删除该 ROB 条目,为后续的指令腾出资源。当然 RAT 中也不再需要 rename 到 ROB1,最新的值已经在 ARF 中。
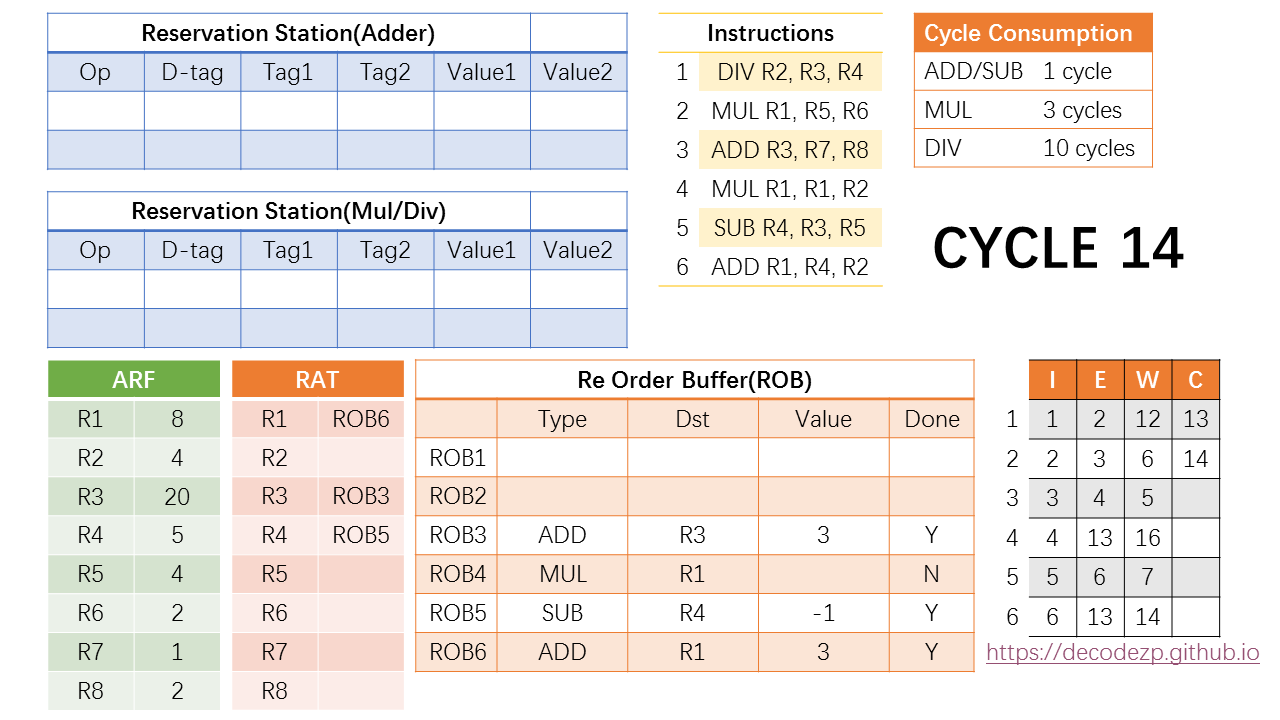
在 cycle 14 中,ROB 中的当前在队列头部的指令,也就是第二条指令也可以 commit 了,按之前的操作,R1 的值也改成了最新的值(8)。
同时,第六条指令也执行完毕,计算的结果写入 ROB6。当然这条指令还不能 commit,因为 commit 需要按指令顺序。
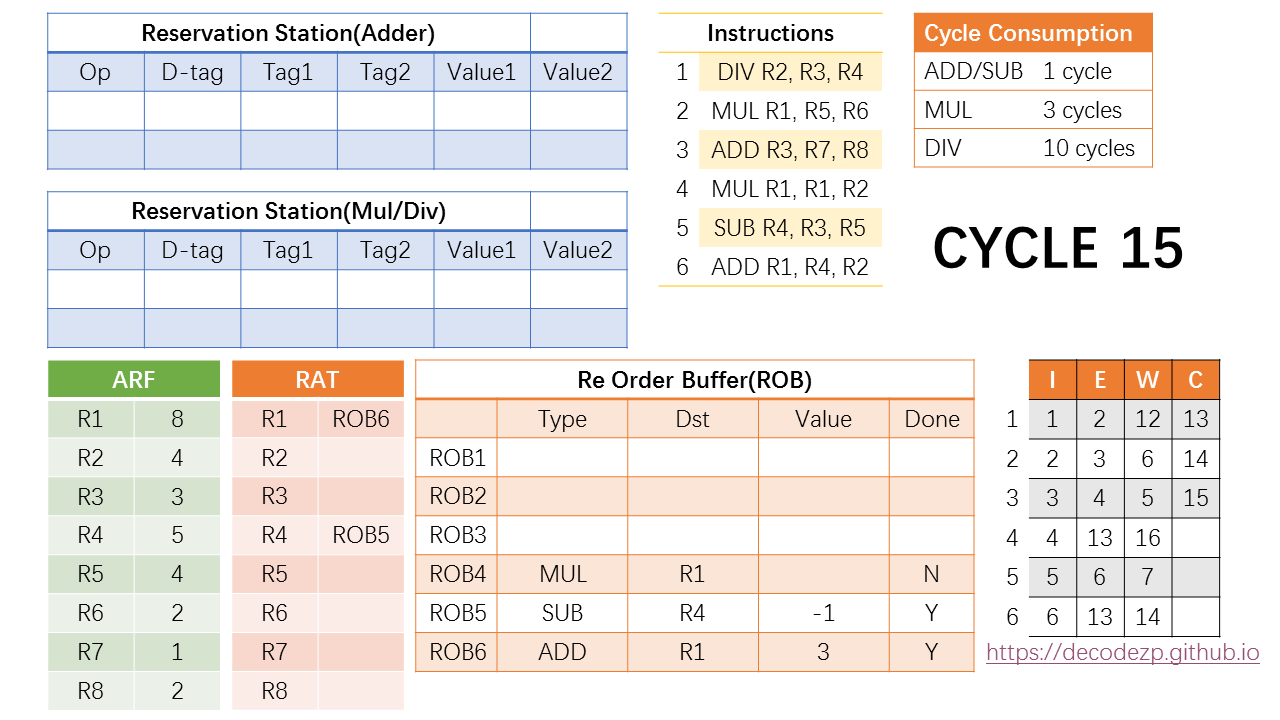
第15个cycle,除了commit第三条指令之外没什么好做的。和以前的操作类似。
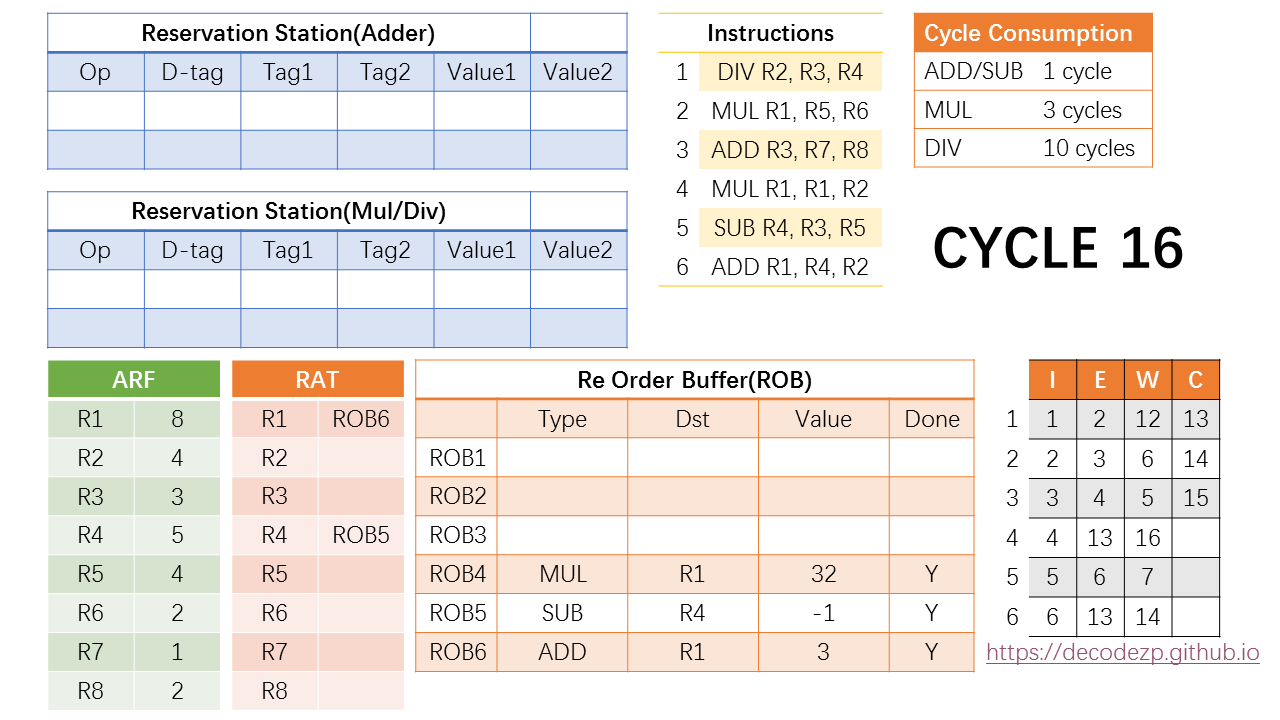
第 16 个指令,第 4 条指令执行完毕,结果写入 ROB4,同时它也是当前 ROB 中在队列头部的指令,可以在下一个 cycle commit。
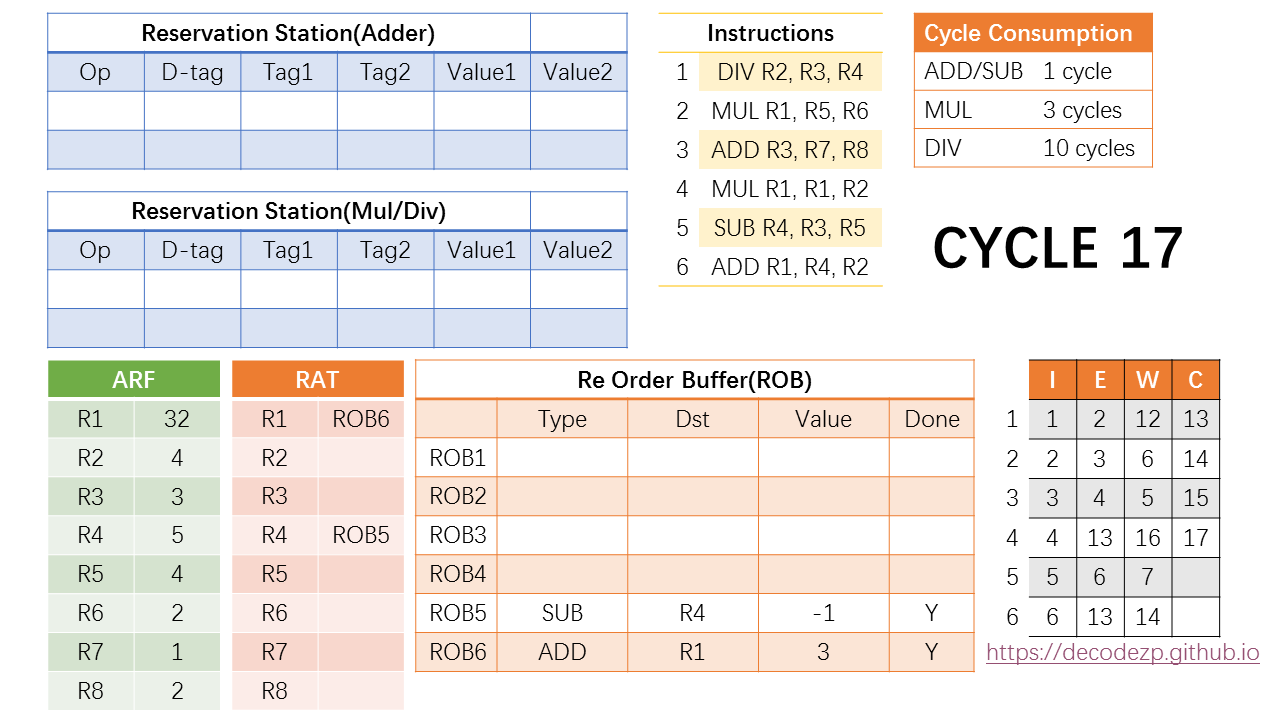
那就commit呗。
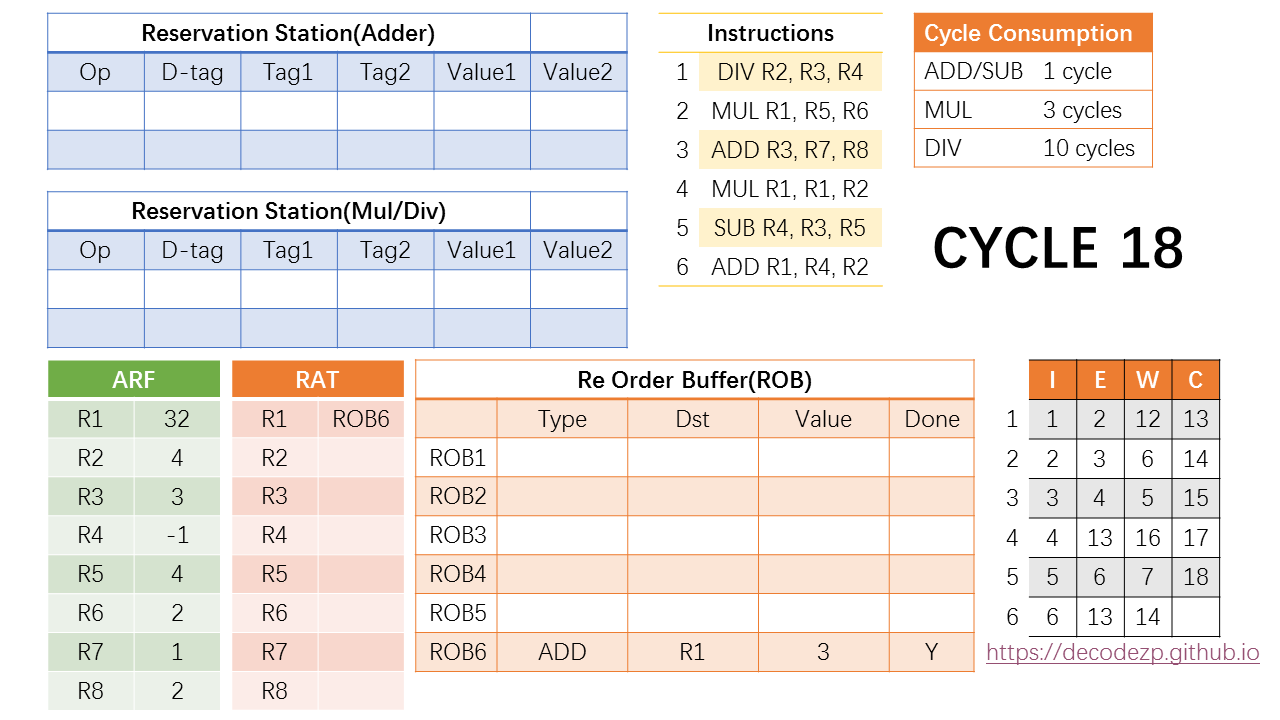
剩下的第 18,19 cycle 想必你也知道该干什么了:把最后的两条指令 commit 掉。
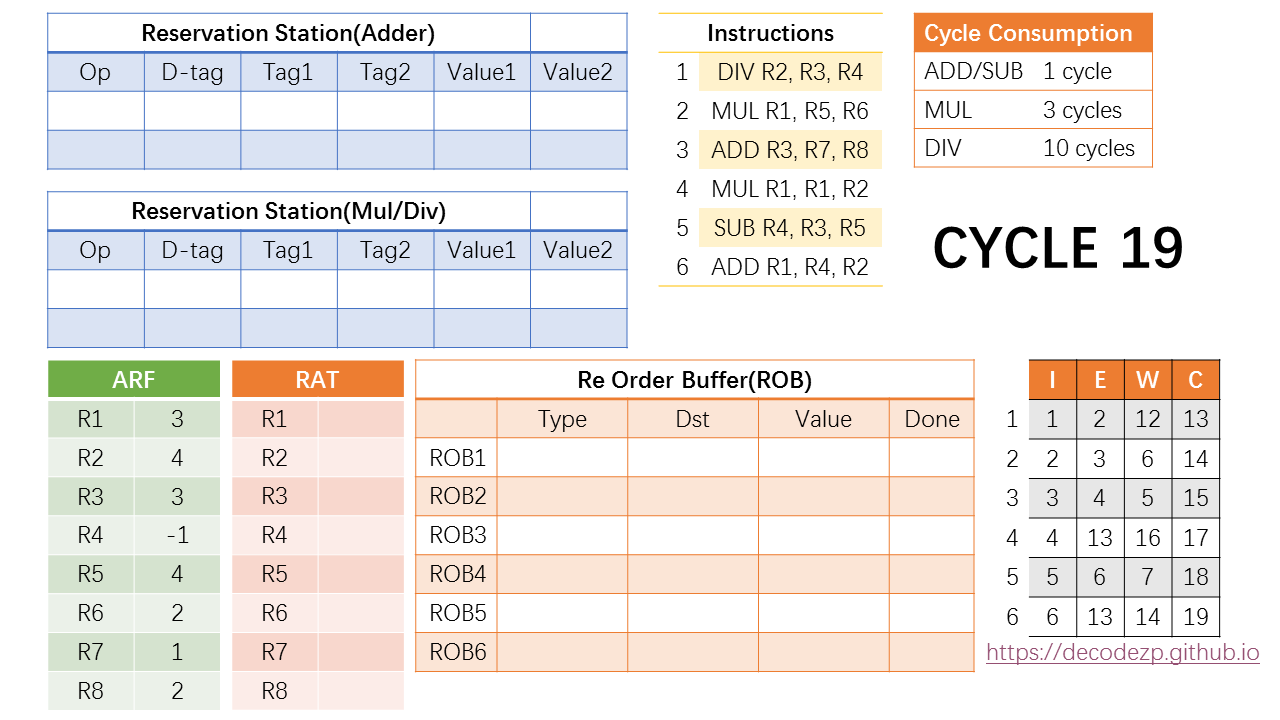
OK,当指令时刻表都完成之后,这6条指令正式执行完毕
关于这几个组件
全部目的都在于通过一个示例解释 RAT, ROB 和 RS 这三个组件的组成、特性和功能。在熟悉了这个例子的基础上可以再去寻找那些传统的“教科书”去印证理解那些大段大段的文字描述。
这个例子其实还缺少一些类似分支转跳,尤其是分支预测失败之后如何操作的说明。但足矣描述清楚 CPU 的乱序执行和顺序 commit 到底是怎么回事。
关于 CPU 微架构,前端和后端的内容基本上介绍的差不多了,后面会开始最后一个部分,也就是内存操作相关的组件的介绍。
Load and Store
这一章节我们讲一下 load 和 store 。
尽管我们将指令load和store指令归类为其他类别的指令中的特殊指令,但所有指令和管道的设计都具有统一的目的:通过消除依赖关系来提高指令级别的并行度(parellarmise)。换句话说
- 通过
branch prediction来消除控制依赖性 - 通过
register renaming来消除false dependencies
需要注意的是
register renaming是针对寄存器的,而不是针对主存的。
主存操作是否也存在依赖关系,如果有我们应当如何解决?
read/write 与 load/store 的不同
load 和 store 是内存操作的两个指令,而 read 和 write 是直接操作内存的动作。在大多数情况下,这两个属术语可以互换,但是在下面的语境中,为了不对他们的含义产生误解,我们使用以下定义来区分:
store是内存操作指令,只有在store指令提交后,才会发生内存写入load也是内存操作指令,但是load指令提交前后,都有可能发生内存读取。原因是load指令能够利用之前存储到load指令相同地址的结果。
寄存器与主存
寄存器和内存共享相同类型的依赖关系。可以在乱序执行期间消除错 false dependencies 关系。
不同的是,内存操作只有在运行时才可以知道操作地址,这就使得判断依赖性变得更加复杂。例如
1 | Load r3 = 0[R6] |
在第三条指令中,将 r4 的值存储到 r7 记录的内存地址,然后第五条指令,从 r1 记录的内存地址中读取数据。我们假设缓存没有命中,如果 r7 的值与 r1 的值不同,没有任何问题;但如果 r7 == r1 ,就会出现问题。尚未提交的第三条指令会让第五条指令读取的值不正确。换句话说这是 RAW true dependencies。
导致这种局面的真正原因是 memory aliasing,当两个指针指向同一个内存地址时,true dependency 就会发生。
load 与 store 示例
假设初始条件如下
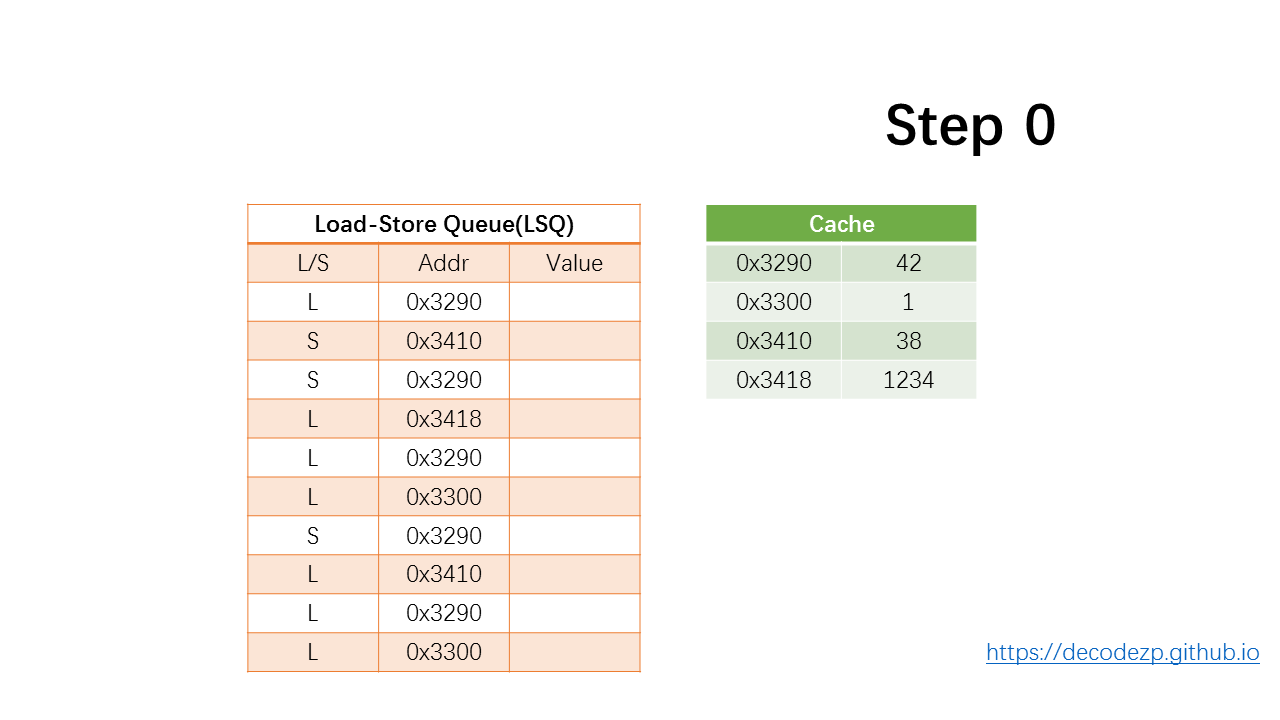
最开始,几个 load 指令和 store 指令被传输到 Load-Store Queue (LSQ) ,有 4 个 address-value 键值对在缓存中。

开始从 LSQ 中执行第一条指令:load from addr 0x3290。
首先检查先前是否有 store 指令将值存储在同一地址。由于这是第一条指令,前面没有任何 store 指令。
然后,在缓存中查找匹配项。在我们假设的场景中,会命中缓存,并将 42 传递到 LSQ 中 Value 的位置。
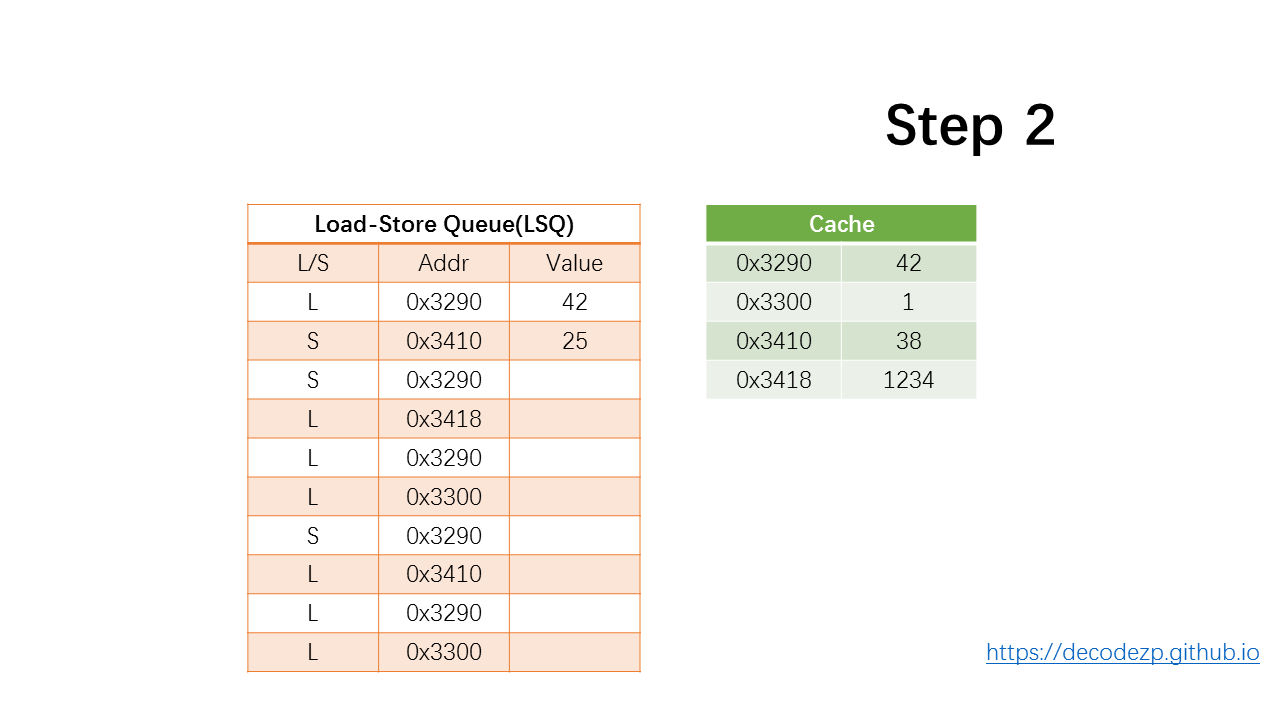
继续执行下一条 store 指令,假定 store 计算出来的值为 25,并将其存储到 LSQ 的 Value 列中。
因为只有提交时,才会写入到主存中
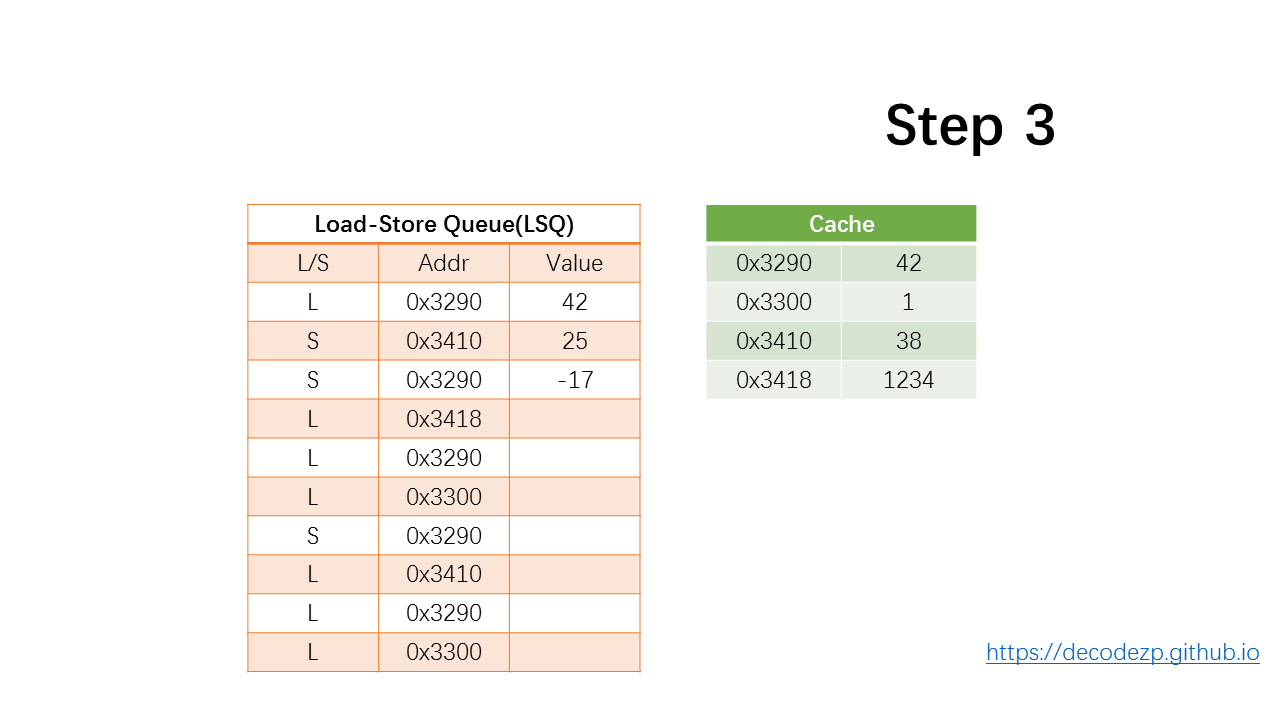
再下一条指令也类似,假设置为 -17。
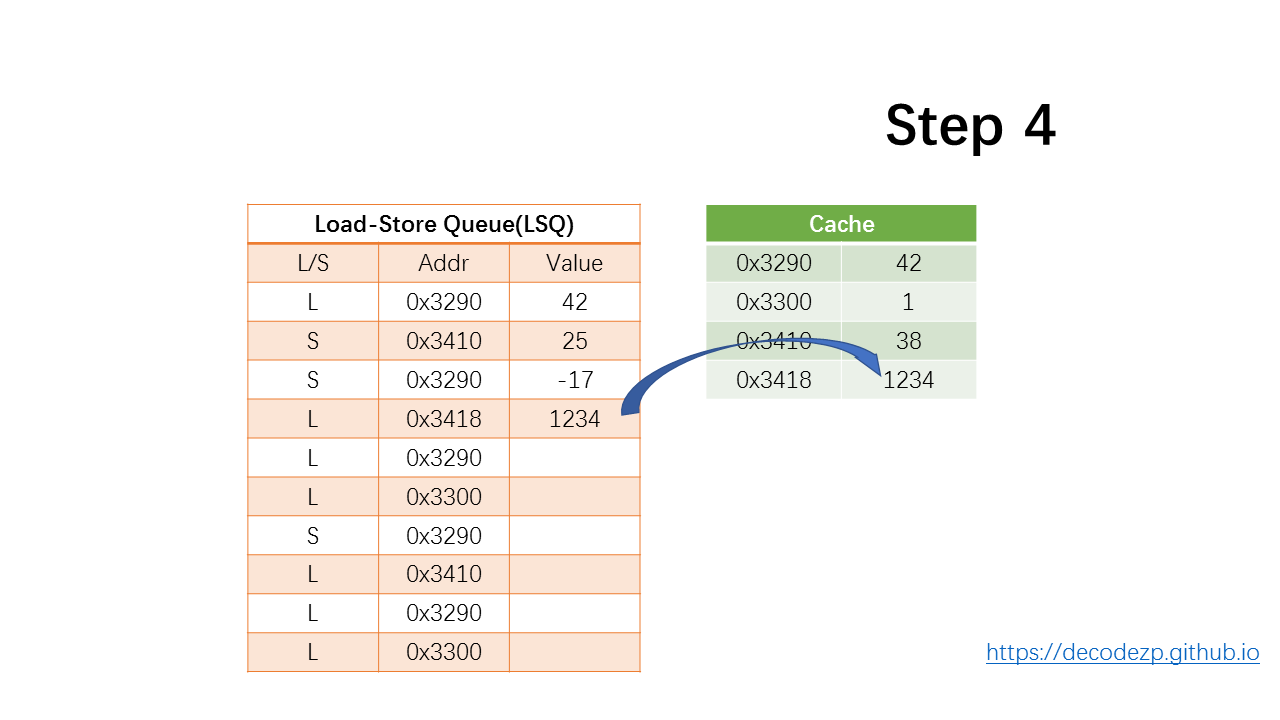
下一条 load 指令,依然会首先检查前面是否有 store 指令写入到相同的位置,发现没有,然后从 Cache 中将响应地址的值传递到 LSQ 的 Value 中。
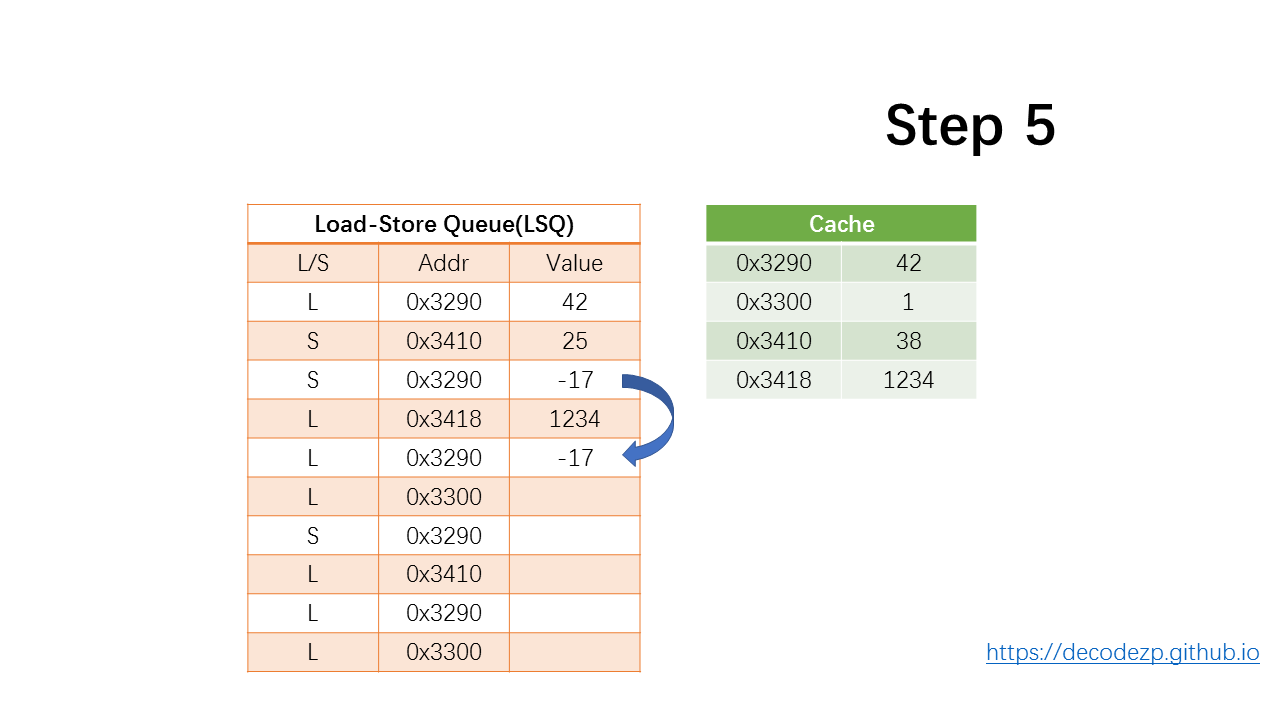
再下一条 load 指令,可以找到之前 store 指令存储到了相同的地址,于是直接将 store 的值读取到 Value 中。这是一个 store-forward 操作。
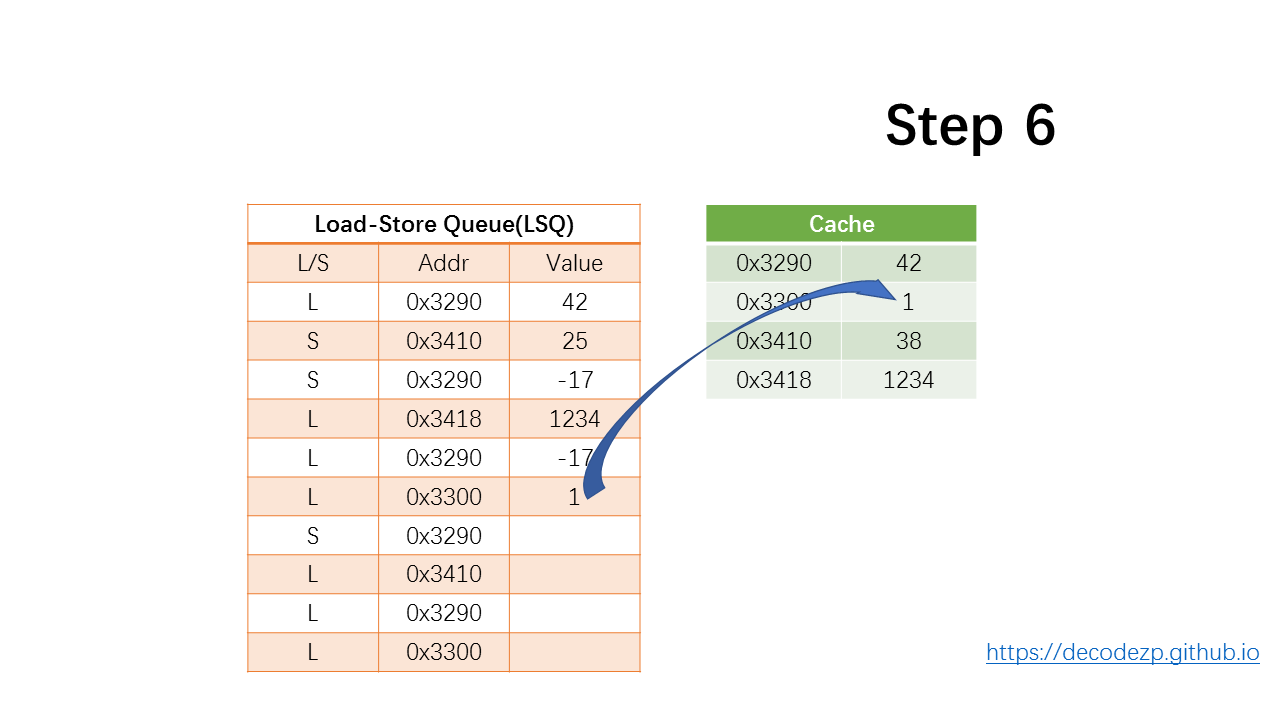
下一条 load 指令会从 Cache 中读取值 1 ,并放入 LSQ 中。
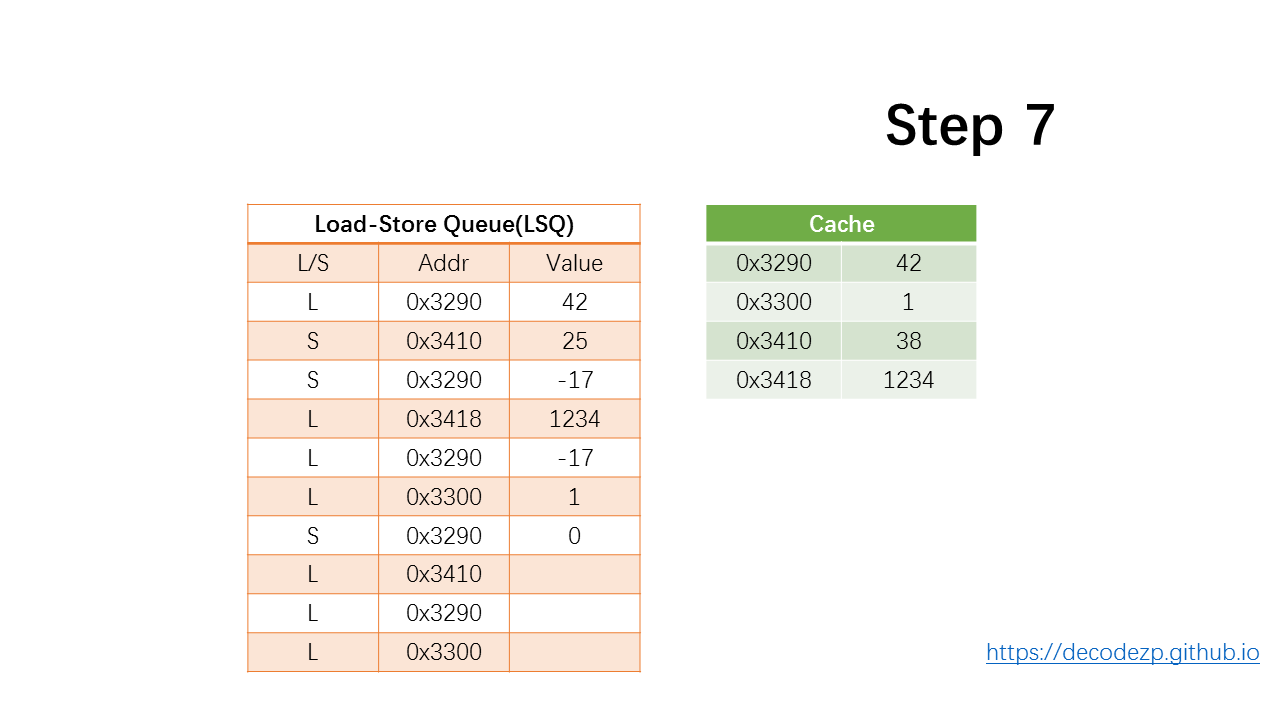
接下来 store 指令,假设计算值为 0 并放入 LSQ 中。
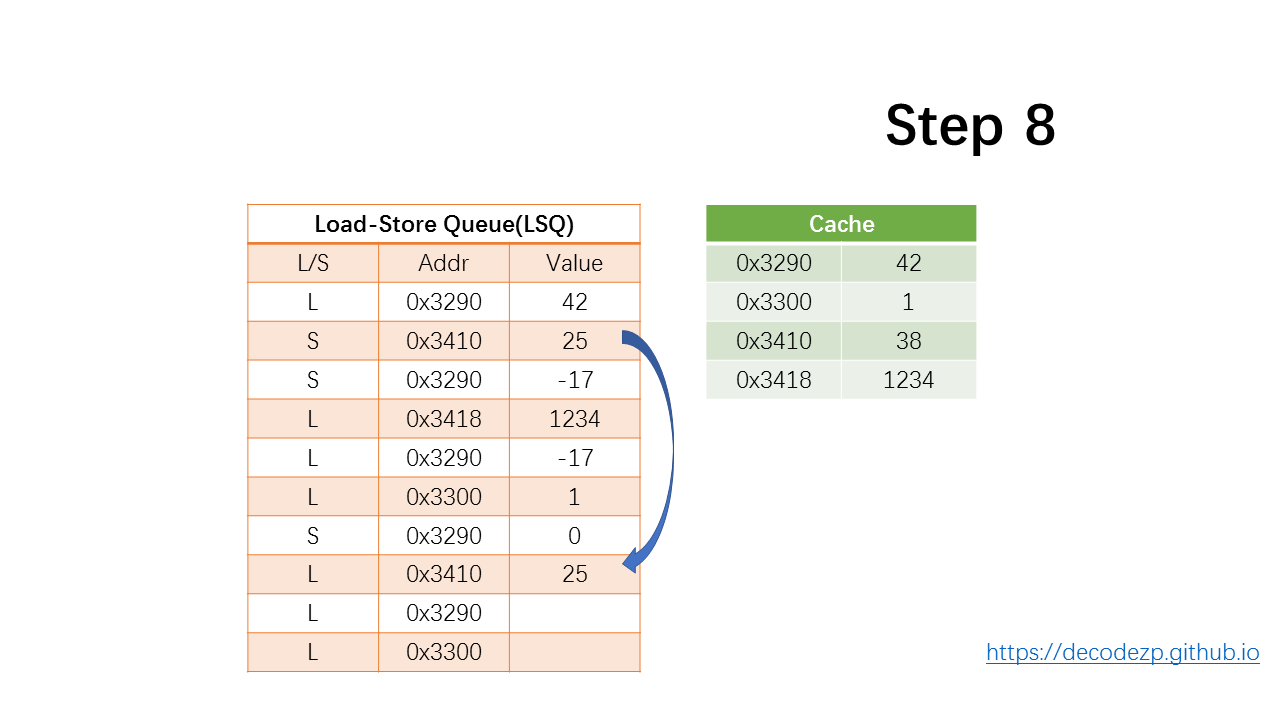
接下来 load 指令,继续通过 store-forward 操作,将 25 放入 Value 中。
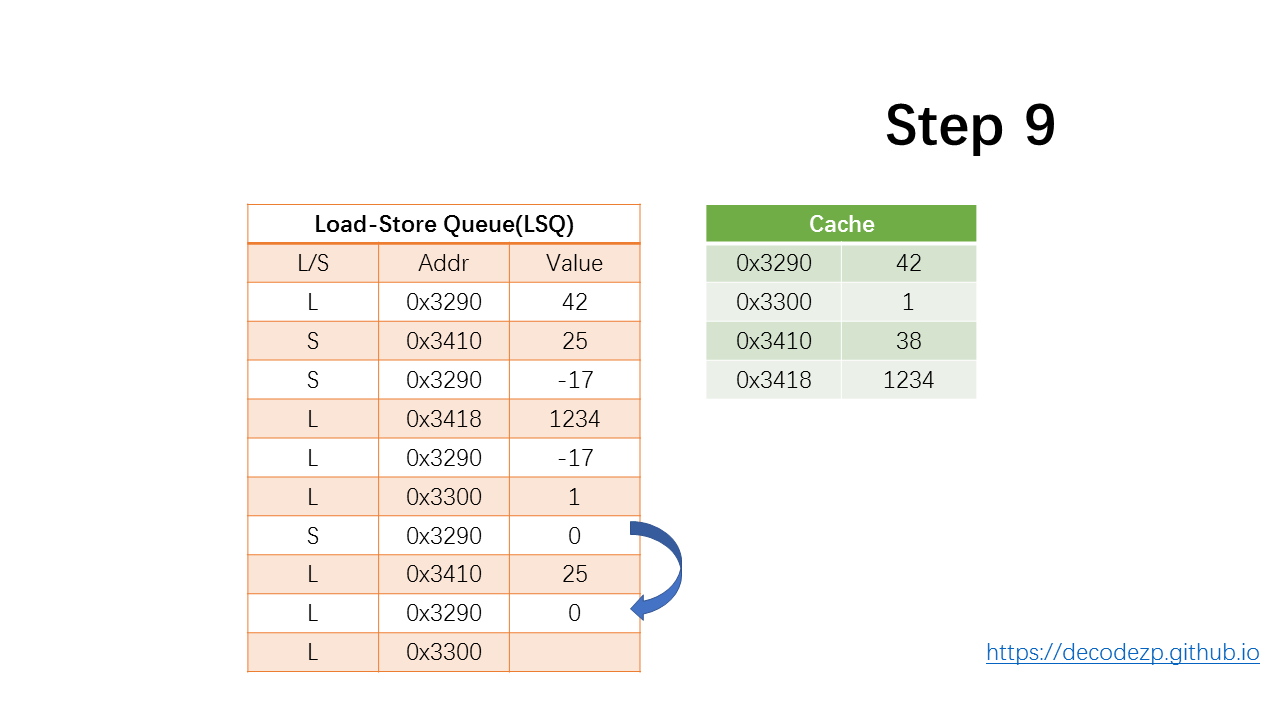
下一条 load 指令,会找到多个 store 有相同的地址,取最接近的一个,将 0 放入 LSQ 的 Value 中。
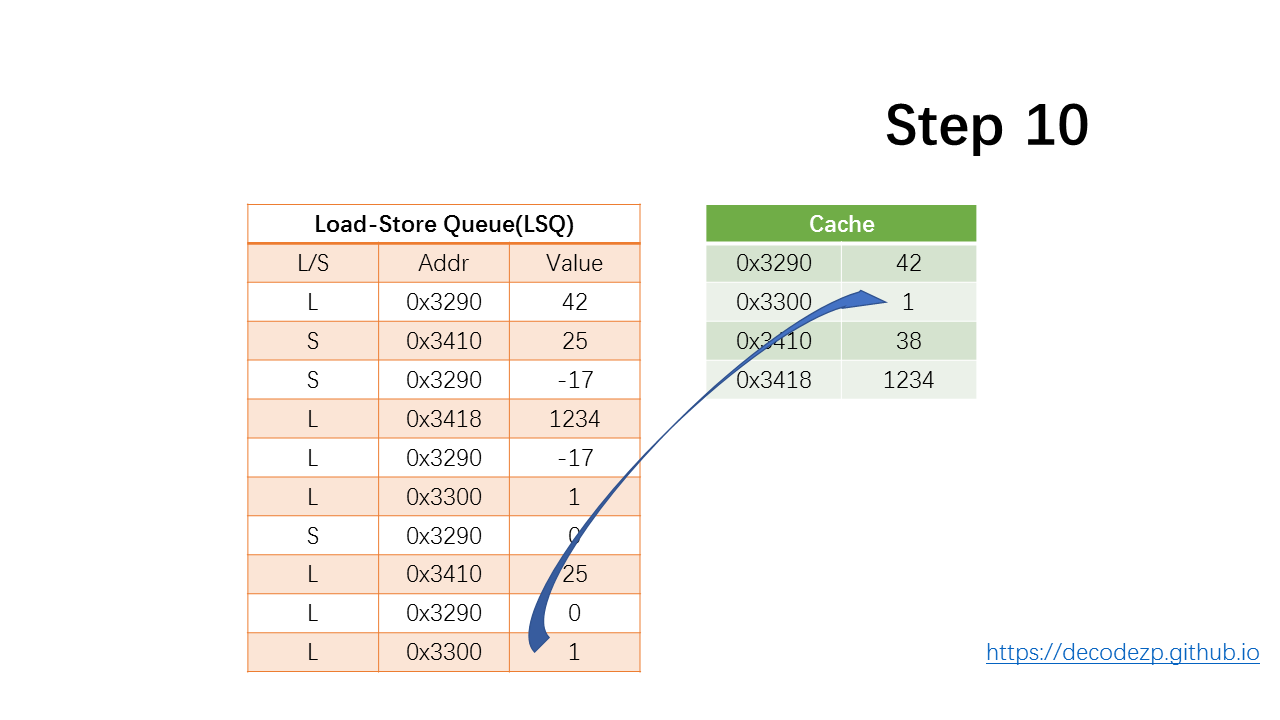
最后一条 load 指令,从 Cache 中将 1 放到 LSQ 中。
然后,将提交指令。
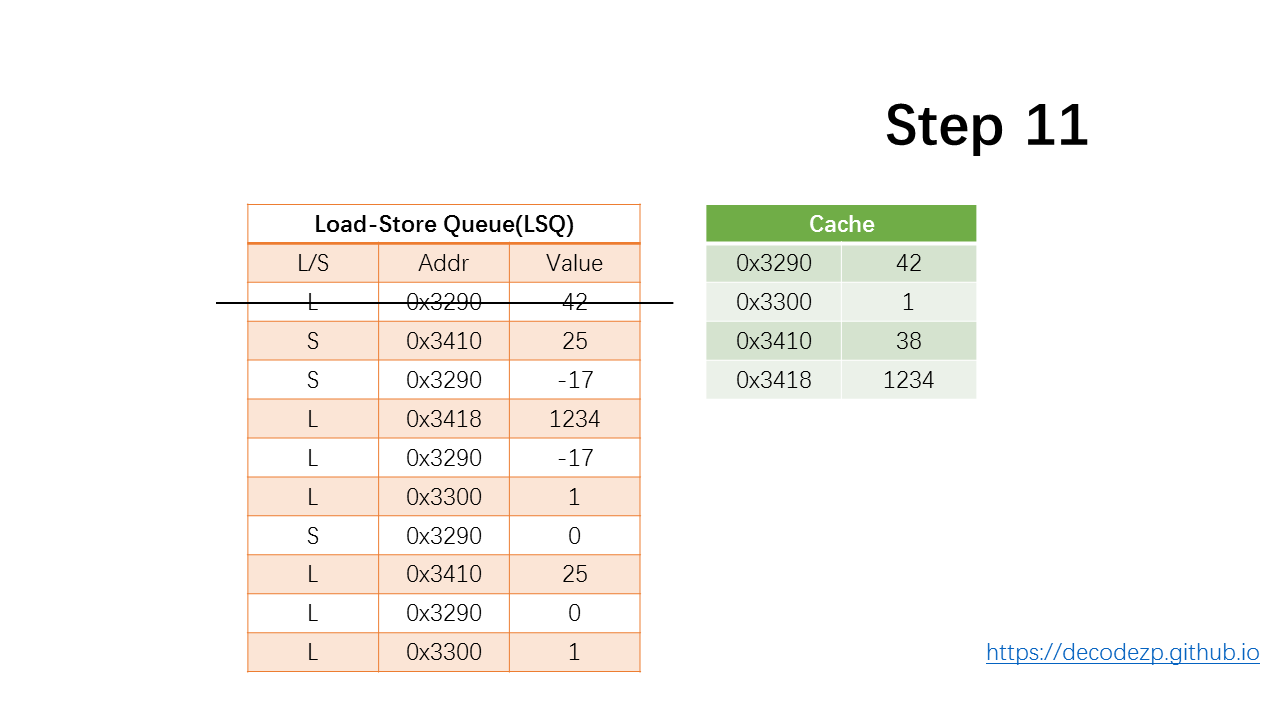
对于 load 指令而言,它只是从 LSQ 出队,因为该值已在执行阶段加载到寄存器中。
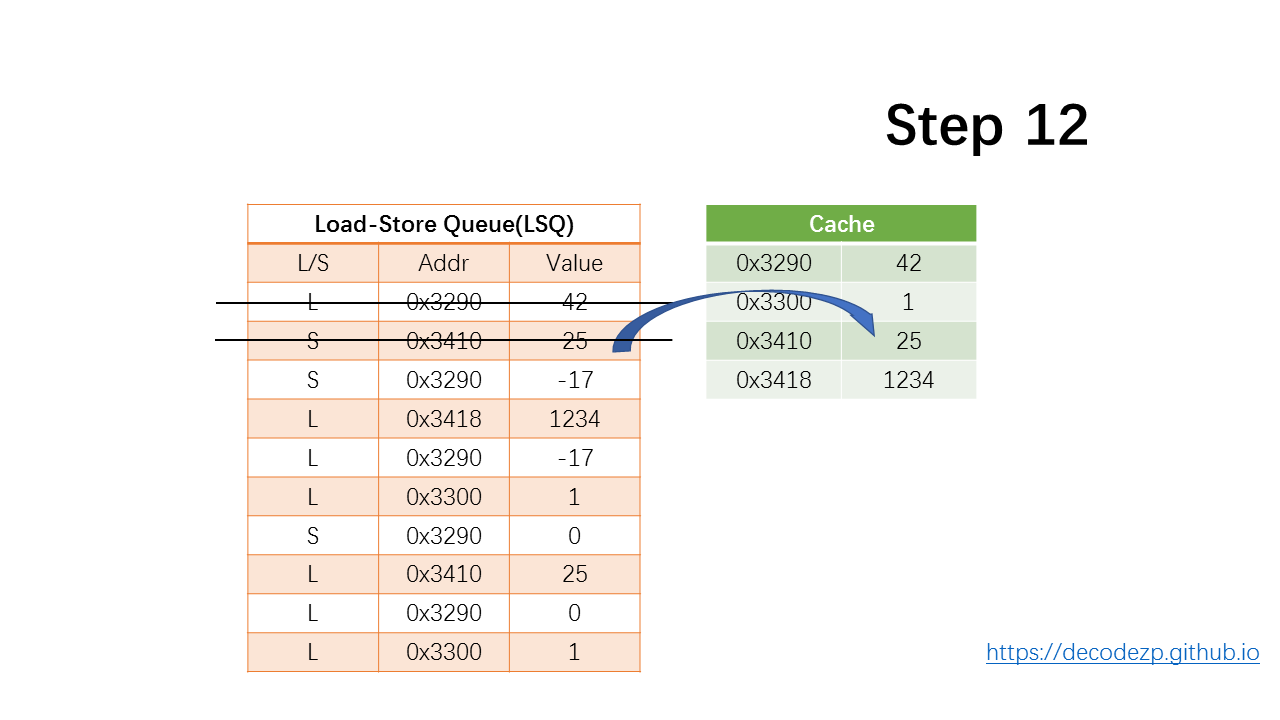
对于store指令,将值更新到 Cache 中,然后出队。
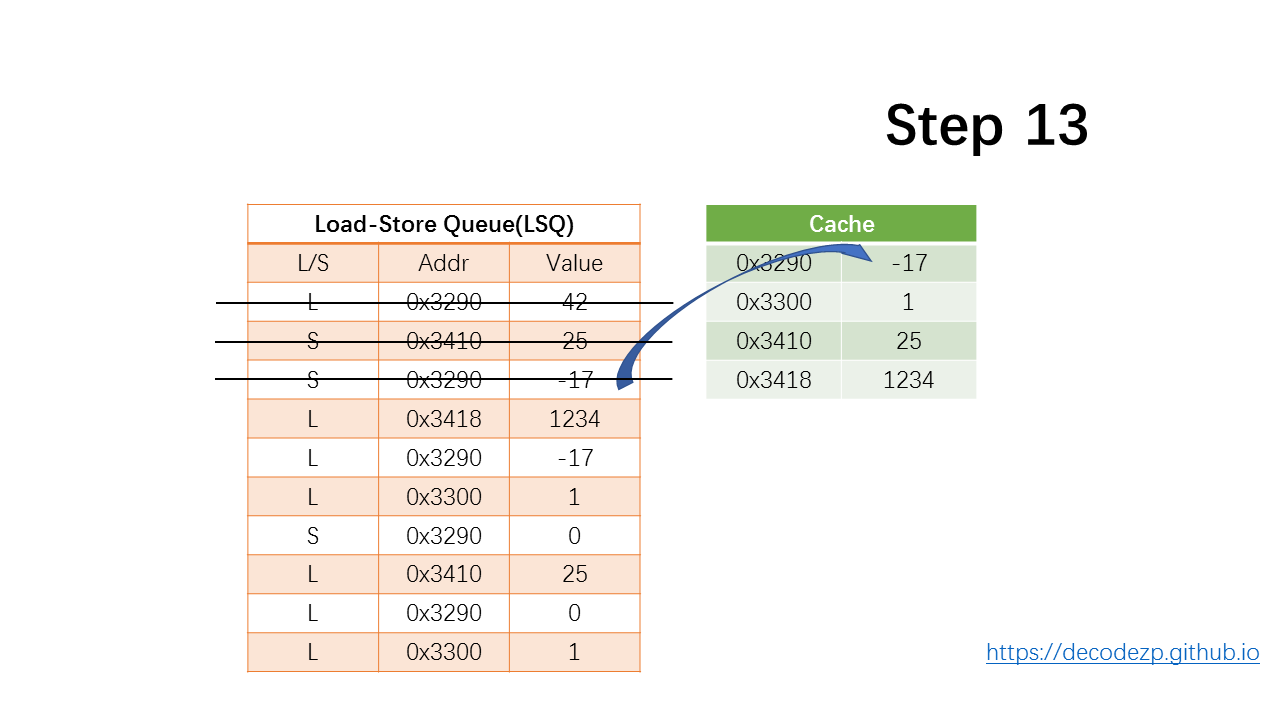
下一条 store 指令,依然是更新到 Cache 中,然后出队。
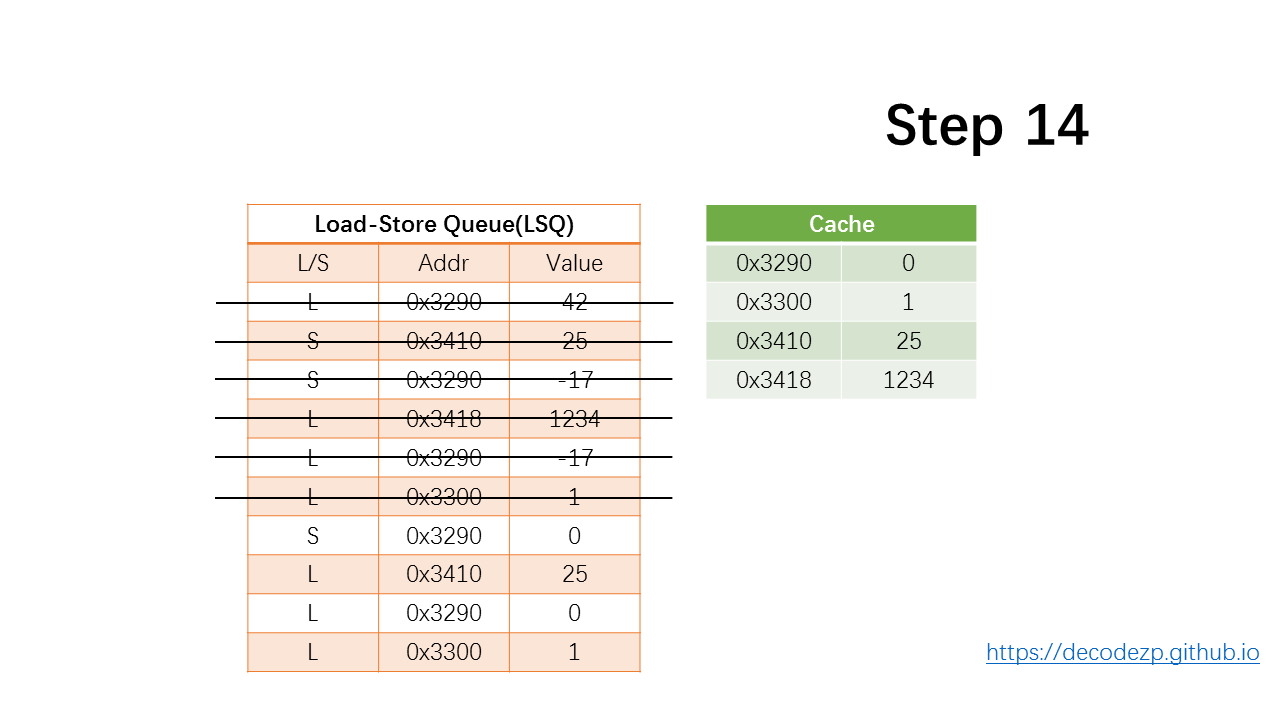
接下来的三条 load 指令,出队。
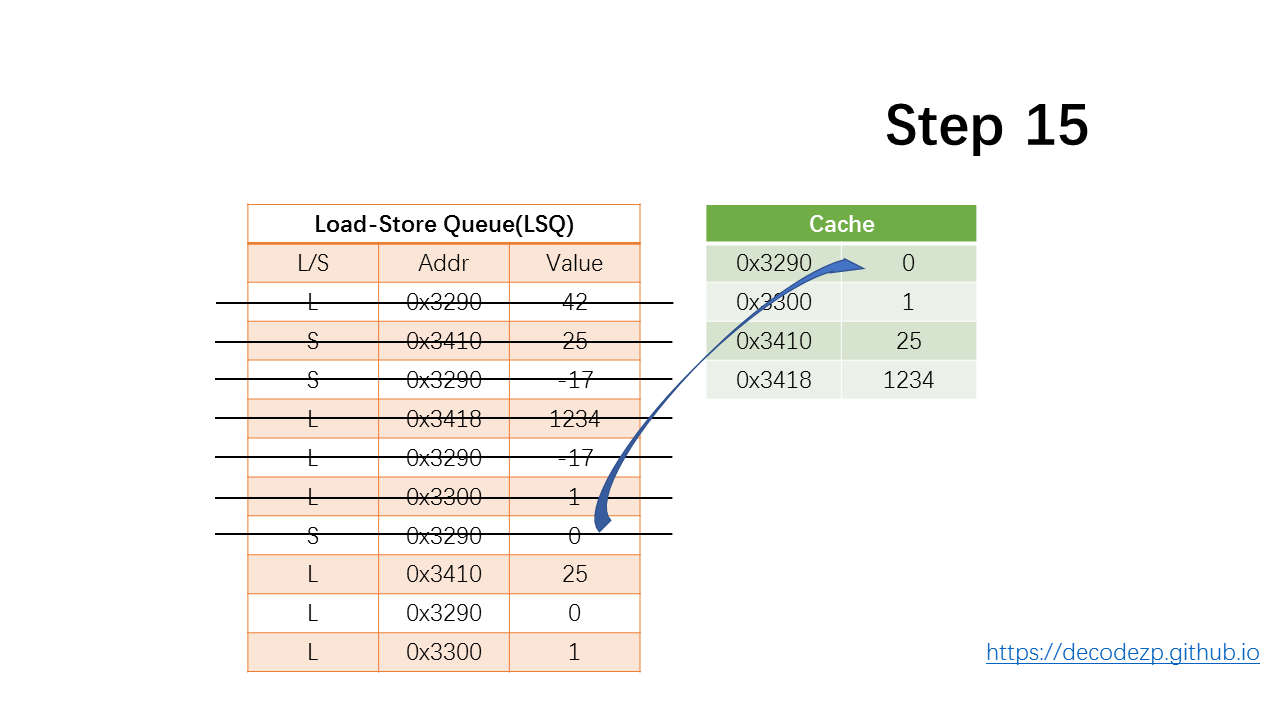
store,更新缓存,出队。
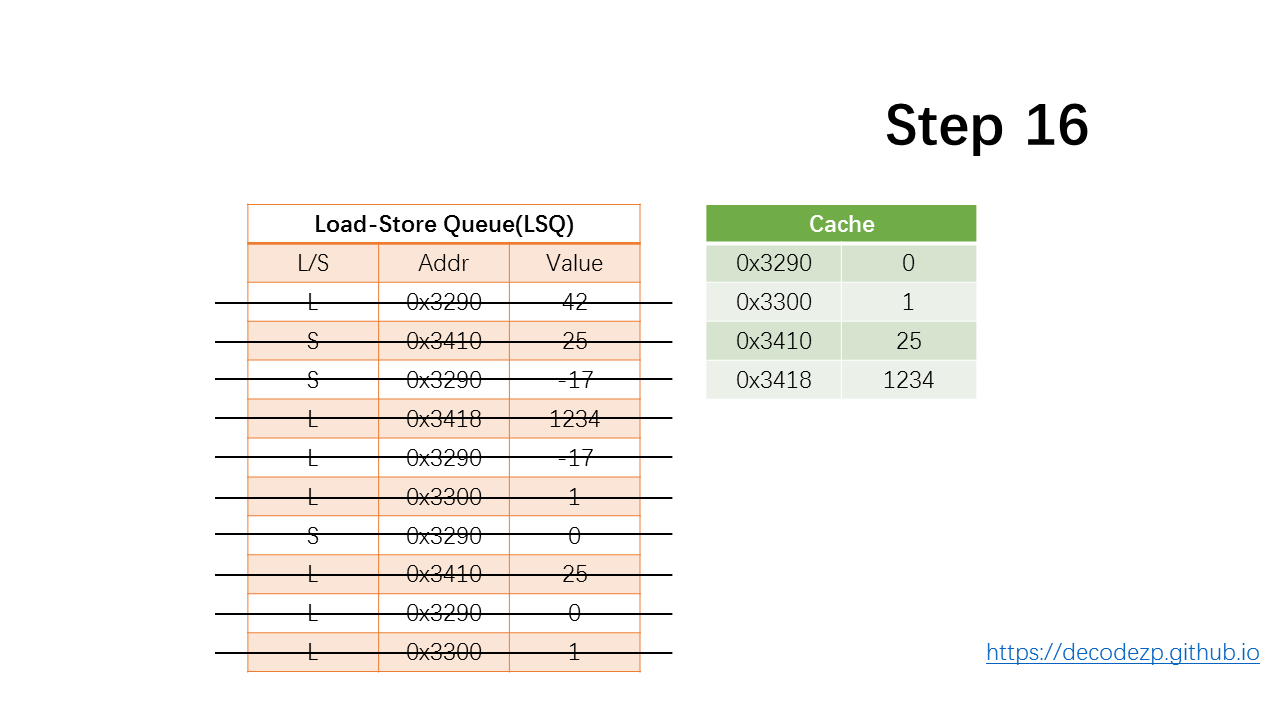
最后三条 load 指令,出队。
之所以 store 仅在提交阶段更新缓存,是因为如果处理器在流水线中检测到预测失败,并且最后一条 store 指令之后的指令需要刷新,则缓存状态不会受到影响,并且如果正确预测时,可以认为从未收到影响。
再次声明
本文全部内容都来自于 DECODEZ “Skylake 微架构剖析” 系列,地址 https://decodezp.github.io/2019/01/07/quickwords9-skylake-pipeline-1/
搬运仅仅为了留作笔记,详细内容请直接访问 DECODEZ 的博客网站 https://decodezp.github.io/

